
 By
DataOps.live
By
DataOps.live

Table of contents
-
What is Data Mesh?
-
The four Data Mesh Principles
-
The benefits of Data Mesh
-
Data Mesh challenges and considerations
-
7 Best practices for Data Mesh implementation
-
A promising new paradigm
Let’s Dig In to Data Mesh: Principles, Examples & Best Practices. Data is one of the most valuable assets in any organization today, offering insights that inform business strategies, shape product offerings, keep customers loyal, and more. Every department in an organization benefits from easy access to data—but it’s not always easy for business users to access the data they need. This piece explores a relatively new architectural approach that aims to solve that: data mesh.
What Is Data Mesh?
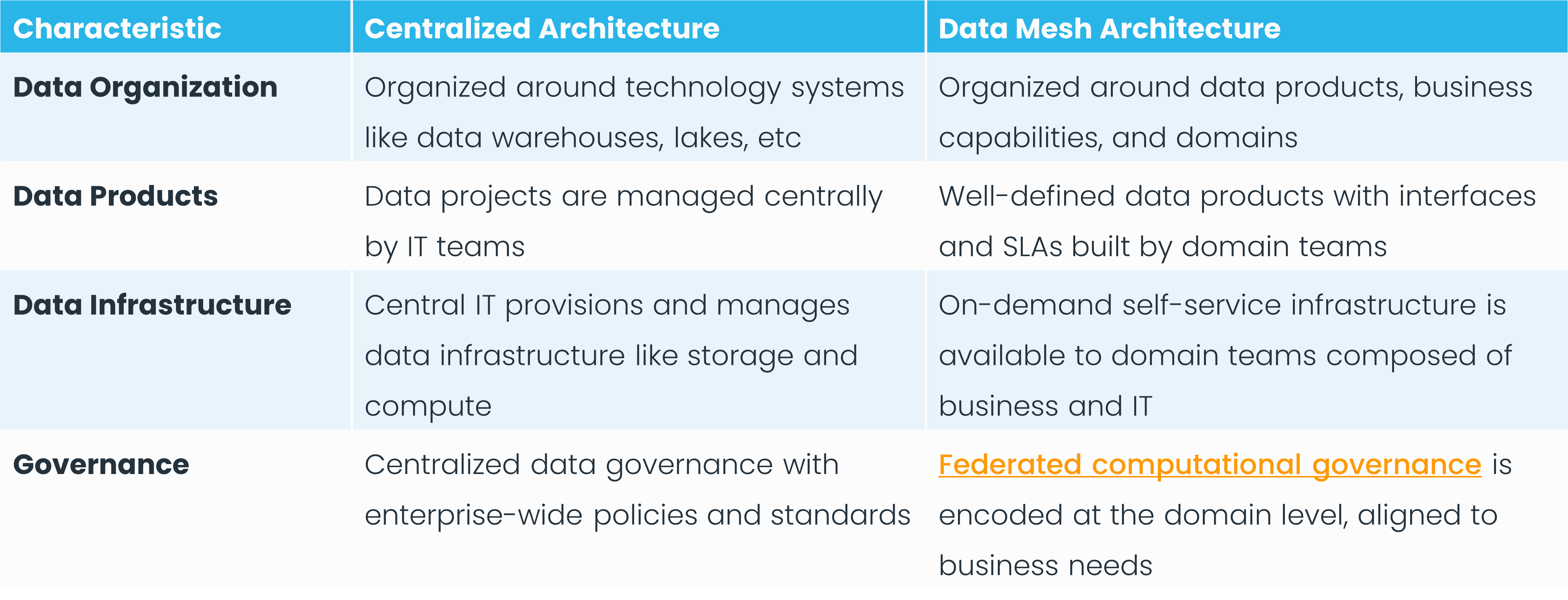
Data mesh is a decentralized architectural approach to managing and governing analytical data at scale that distributes data ownership across business domains. It treats data as a product, and the domain teams that best understand the data own it and govern it.
The goal is to make data accessible to everyone to increase flexibility, decrease central bottlenecks, and align data management with business goals. Ultimately, these things enhance the value that an organization gets from its data.
To fully understand data mesh, we must explore its four principles.
The four Data Mesh Principles
When Zhamak Dehghani developed the distributed data mesh architecture, she outlined four separate but interrelated principles designed to achieve its goals:
Domain-oriented data ownership
Data ownership has become an important consideration as organizations strive to become data-driven. The domain-oriented data ownership and architecture approach of data mesh seeks to address this goal by giving the business teams closest to the data the responsibility of managing it.
By giving domains ownership of their data, you decentralize the responsibilities that would traditionally lie with a centralized data team. This allows for more agility and responsiveness to specific business needs.
Data as a product
Data mesh calls for a fundamental shift in how organizations think about data. Instead of looking at data as a byproduct or secondary asset, organizations treat data as products that require as much attention, planning, and care as any other product. This means it must be well-defined, reliable, and fit for purpose.
A data product owner works with a clear set of stakeholders to define the use cases it aims to support. They then manage the entire product lifecycle, ensuring the data product remains relevant, up-to-date, and aligned with their stakeholders’ evolving needs. And since data product owners deeply understand how their customers use their data products and the data itself, data value increases.
What is a data product? Get an in-depth introduction here!
Self-service data infrastructure
Data mesh requires a self-service data platform for successful implementation. Self-service infrastructure alleviates bottlenecks often associated with centralized data teams. It should contain all the tools and technologies domain teams need to build, deploy, and maintain data pipelines, applications, and products.
However, for decentralized self-service infrastructure to work across an enterprise, all teams must use a set of standardized tools and practices. This ensures consistency and makes it easier for teams to collaborate and share data. In a self-service environment, it's also important to have mechanisms for tracking usage and associated costs to make sure resources are being used efficiently and for better planning and allocation of data storage and processing capabilities.
The self-service environment also needs to be accessible for non-technical users. User-friendly interfaces like dashboards or other visualization tools that make it easy for business users to derive value from data are essential. It's also crucial that data is easily discoverable. This often involves creating a data catalog listing all available data products, metadata, quality metrics, and other relevant information.
Federated data governance
Data mesh uses a federated system of governance that aims to balance centralized oversight with decentralized data ownership. Unlike traditional models where a central team governs all data, federated governance distributes some of this responsibility to domain or business unit teams. Each team is accountable for the quality, security, and compliance of its own data within the framework of organization-wide policies and standards.
This approach allows for more agility and specialization, as individual teams understand their data best. However, it also calls for standardized tooling, metrics, and protocols from the central team to provide consistency and compliance across the organization. Federated governance thus combines the best of both worlds: it maintains global standards while empowering local teams to be more responsive and innovative.
Take a deeper dive into the importance of federated governance in data mesh.
/banner-red.svg)
Build, test & deploy data products for
your data mesh with DataOps.live.
The benefits of Data Mesh
A cultural and organizational shift in data ownership often results in the following benefits:
Faster time to value: By empowering domain-specific teams to handle their own data needs, data mesh eliminates bottlenecks, enables quicker experimentation, and reduces time spent on data preparation. Standardized tooling and self-service infrastructure further streamline processes, accelerating the journey from data to actionable insights.
Increased scalability: Data mesh is designed to scale horizontally, meaning it can easily accommodate growing data volumes and complexities without requiring a complete overhaul of the existing system.
Flexibility: Data mesh is technology-agnostic, allowing organizations to use the best tools for their specific needs. The architecture can evolve and adapt to changing business requirements and data landscapes.
Improved data quality: Treating data as a product encourages teams to focus on the quality and usability of their data, as they are responsible for it end-to-end. Data mesh promotes a culture of data literacy across domains, allowing teams to hyperfocus and specialize on their domain data to create high-quality and reliable products.
Increased innovation and collaboration: The data mesh approach encourages collaboration between data product owners and data users, fostering a culture of innovation. By making data more accessible and understandable, data mesh empowers more people within the organization to make data-driven decisions.
Actionable accountability: the domain principle creates accountability for the data product owner enabling a value-driven conversation between data product producers and consumers.
Data Mesh challenges and considerations
Like every new method or approach, data mesh faces two significant classes of challenges: organizational and technical.
The shift to a data mesh approach is as much an organizational change as it is technical. As domains take on new responsibilities, they may need to hire or upskill to gain the expertise necessary.
A complete cultural shift from centralization to federation also requires significant commitment from technical and business stakeholders. There may be resistance, particularly from data security and governance teams. Data democratization can raise data privacy and security concerns. It calls for robust security measures, access controls, and policies to govern every domain team member's level of access to mitigate any risks.
Finally, the federated data mesh architecture brings technical challenges. It becomes more difficult to ensure interoperability of technology and data models across different parts of the data mesh; it’s harder to monitor and observe the health, performance, and usage of data products across the mesh; and without the proper controls, there’s a risk of data duplication or security issues. Building a self-service platform that supports diverse data sources, multiple connectors, and tools while allowing smooth data flow in the product lifecycle is also no easy feat.
But with the right tools and done correctly—data mesh is a beautiful thing!
/banner-green.svg)
See data mesh in action:
Read the Roche case study.
7 Best practices for Data Mesh implementation
Implementing a data mesh is a complex undertaking that requires careful planning, coordination, and execution. Below are seven best practices that can guide you through the process. The first four address organizational challenges, while the last three will help overcome common technical obstacles.
1. Get executive buy-in and alignment
Change is never easy. Senior leadership support will be crucial for allocating resources and driving organizational change. Make sure they understand the value and long-term benefits of moving to a data mesh architecture.
2. Invest in training and upskilling
Domain teams may not have the necessary data engineering or data science skills. Invest in training programs to upskill these teams so they can effectively manage their data domains. Invest in the data product owner role.
3. Monitor and Measure
Implement robust monitoring and observability tools to track your data mesh's performance, usage, and health. Use metrics and KPIs to measure the success of the implementation and make data-driven decisions.
4. Iterate and Improve
Data mesh is not a "set it and forget it" architecture; you’ll learn lessons (like these) from your first implementation. Continuously gather feedback from users and domain teams, and be prepared to iterate and make improvements. This includes not just technical adjustments but also possible organizational changes.
5. Prioritize Data Quality
Answer the question: can I trust my data? Implement frameworks and tools to monitor and improve a data product’s data quality. Poor data quality can undermine the value of the data product, so this should be a high priority.
6. Enable discoverability
Make it easy for data consumers to discover and access the data they need. Implement a centralized data product catalog or directory that lists all available data products with metadata, quality metrics, and other relevant information.
7. Build for Scalability
Design your data mesh architecture to be scalable from the start. This includes choosing the right technology stack and designing data models and workflows that can handle increased load.

Learn more about how DataOps.live
helps you build data products.
A Promising New Paradigm
Data mesh offers an intriguing new paradigm for data architecture that aims to increase agility, reduce bottlenecks, and align data management with business goals. By decentralizing data ownership to domains and empowering teams through self-service data infrastructure, organizations can enhance data's value and accessibility.
However, implementing a data mesh requires careful planning and execution to address both organizational and technical challenges. Success rests on securing executive sponsorship, enabling discoverability, monitoring usage, and continuously gathering feedback to iterate and improve. With the right vision, commitment, and tools, data mesh promises to unlock immense potential from an organization's data assets.
/banner-pink.svg)
Request a demo
Speak with a DataOps.live expert today.



