
 By
DataOps.live
By
DataOps.live

Our latest masterclass (held on 9 November 2021) comprised a technical session between our very own Guy Adams and Bryon Jacobs of data.world. The subject was data cataloging—gathering (or collecting) all the metadata from different systems and publishing it in a data catalog.
As we have come to expect, Guy started the session off with a valuable intro to DataOps and #TrueDataOps, the foundation on which the DataOps.live platform was built. This part of the discussion can best be summarized as follows:
Instead of cobbling together technologies and methodologies on top of an existing data environment, we started with DevOps, took the parts that were relevant and useful to data, and added in extras like automation, environment management, as well as the management of state in databases or data warehouses containing petabytes of data.
The resultant philosophy is known as #TrueDataOps and is described on the website by the same name. As highlighted above, this paradigm underpins our DataOps platform and our company’s raison d’etre. Along a similar vein, it is worth noting that our philosophy and data.world’s philosophy are very similar in this regard. We both advocate a very heavily automated approach to data management ecosystems.
Before we dive into a discussion on why one-click (or automated) data cataloging is the best way to load metadata into your data catalog, it is worth noting that we have just published a book, DataOps for Dummies.

A brief introduction to DataOps.live
It is vital to note at the outset of this discussion that we are a Snowflake-only platform. This is because Snowflake is the only data cloud that has the requisite set of functionalities, allowing for a proper implementation of the #TrueDataOps philosophy.
Our platform includes functional and data mesh tools, including ingestion, transformation, testing, observability, and reporting and data cataloging. In summary, our DataOps platform sits as the automation, orchestration, observability, as well as reporting and data cataloging layer that sits on top of all these tools.
The data catalog: The last step in our DataOps pipeline
As highlighted above, this master class deals with the reporting functionality as indicated in the diagram—the last step in the DataOps pipeline. In summary, this step is responsible for the following functions:
- Generates automatic documentation
- Creates internal reporting views
- Interacts with external reporting and data catalog applications
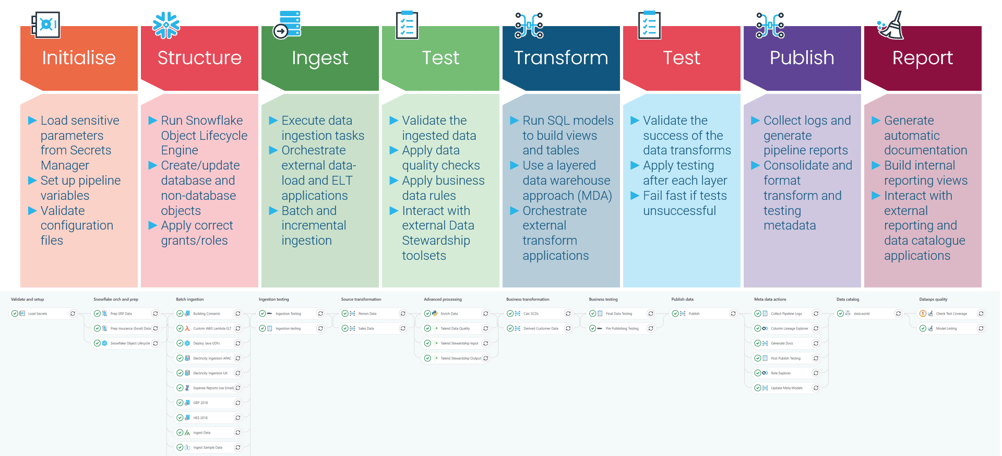
By the end of the pipeline run, we would have collected a ton of information about every step in the pipeline, such as where the data came from, what we did with it, how we transformed it, what tests were applied, what governance structures were applied, and so on.
This information is usually serviced in a data catalog. And this is where our processes are divergent from traditional or manual data cataloging methods.
To expand on this point, let’s first consider an overly simplified manual data cataloging method. In essence, metadata is harvested or scraped from the data platform, enriched by data stewards or personas, added to a single data catalog, and used by the business.
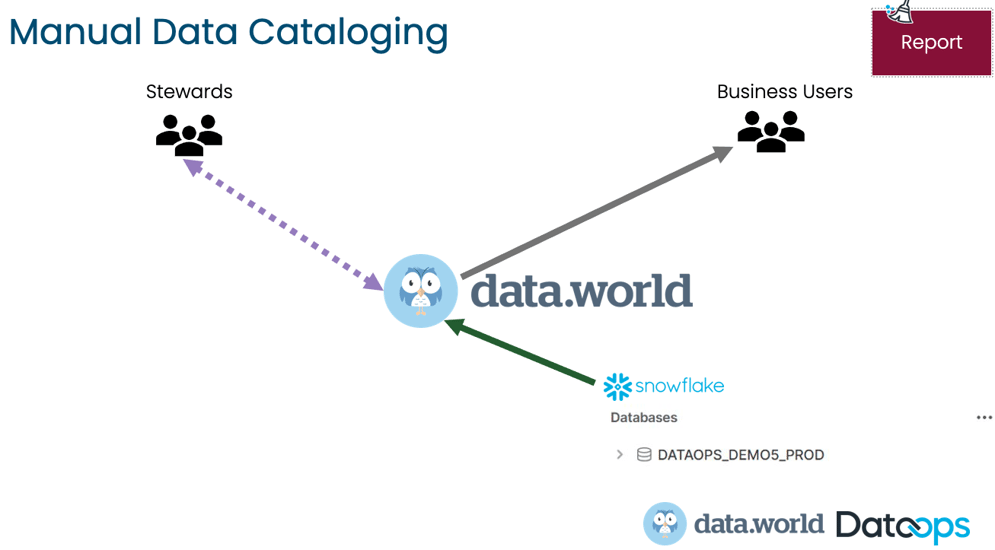
This process is highly time-consuming; therefore, it is unreasonable to expect a data steward to maintain more than one data catalog physically. Additionally, the biggest challenge with this manual process is that metadata from small functional changes are not always added to the data catalog. In today’s world, where organizations must manage petabytes of data, there is just too much metadata generated to handle in a manual process.
One of the most pertinent points of #TrueDataOps and our DataOps pipeline structure is that it allows us to align different environments with each other. In a typical organization, there are at least three data environments: dev, qa, and prod, each with a matching data pipeline.
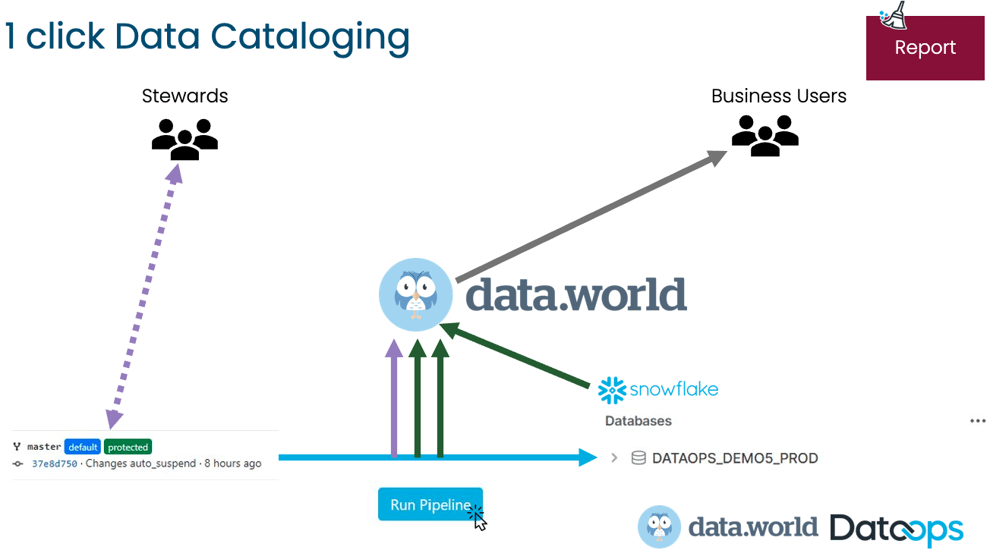
As described above, the manual data cataloging process can only have one data catalog. Juxtapositionally, there is a data catalog for each environment and in each pipeline in an automated process. Also, the advantage of including the data catalog at the end of the pipeline is that all the metadata collected during the pipeline run is automatically published in the data catalog.
It is worth noting that business users don’t care where the data catalog’s contents come from. They still use the same data catalog. In fact, they will more than likely be extremely appreciative that there is more valuable information stored in the data catalog using the automated cataloging method.
Testing that the metadata pushed to the data catalog is correct and what we expect is now also part of the pipeline. The pipeline does not complete its run until every step is has been successfully completed. The pipeline stops as soon as there are any errors at all.
Lastly, the question that begs is: Why do we care about one-click data cataloging?
By way of answering this question, let’s consider the following points:
- Extensive automatically generated metadata is published to the data catalog.
- It is possible to maintain multiple versions of the data catalog, one for each environment.
- Data catalog changes are deployed alongside functional changes. Everything is promoted as a single atomic change instead of lots of different changes.
- Version control is implemented, allowing for the verification and approval of any data catalog changes.
- If necessary, the data catalog changes are easily rolled back, along with the connected functional change.
Conclusion
While it seems as though this master class only contained a lot of theoretical content, it is not so. Most of this master class was spent building and running a simple pipeline showing how our DataOps platform integrates with data.world’s data catalog.
In summary, the key theme of this master class is that one-click data cataloging forms an integral part of any data ecosystem. And data.world’s data catalog is the perfect partner to our DataOps platform for Snowflake, including our DataOps pipelines.
Watch a recording of the webinar here.
Ready to get started?
Sign up for your free 14 day trial of DataOps.Live on Snowflake Partner Connect today!




