
 By
DataOps.live
By
DataOps.live

A novel approach to solving analytical data challenges, data mesh is rapidly gaining ground—and for good reason.
“Data mesh and its principles are an increasingly hot topic,” says Chris Atkinson, Global Partner CTO, Snowflake. What makes it particularly interesting, Chris says, is that “it’s a combination of a cultural shift in organizations and a technical shift in how we look at analytical data, how we approach its usage and distribution.”
As businesses move towards a data-driven culture to drive competitive advantage and gain more insightful decision-making, Chris says the reality is that despite a significant rise in investment in data, particularly analytics and Big Data, tangible returns have fallen.
He continues, “For years, businesses took a monolithic approach to analytical data, with centralized IT services. This led to the rise of ETL and ELT, and with the domains (business lines) sitting outside the structure. Cycle time is the killer of all processes, and this set-up created huge cycle time.”
The solution—moving analytical functions into business domains—itself led to analytical silos, creating islands of information with interoperability and other challenges to solve, with a continued need for ETL and ELT across the different pipelines and silos: “Spaghetti, in short, in the face of ever-increasing data-driven demands from the business, with more data generated each day, and more access required.”
Data Mesh is a way to solve this. A cultural solution combined with a technical solution. Chris Atkinson says it is founded on four pillars:
- Empowered Domain Ownership—letting the experts do their jobs
- Cross Organizational Transport—enabling consumption through Data Products
- Self Service Analytical Platform—reducing costs, improving agility
- Federated Governance—the ‘glue’ that holds the process together, ensuring interoperability and compliance
Data Mesh in the Real World
In a real-life example of data mesh, the DataOps.live platform is helping data product teams in the world’s largest biotech company, Roche, to orchestrate and benefit from next-generation analytics on a self-service data and analytics infrastructure comprising Snowflake and other tools.
Roche Diagnostics had previously pursued a number of initiatives to unlock the value of its data, but each had its limitations. “I chose to pursue a forward-looking data stack and, on the architecture side, a novel data mesh approach,” says Omar Khawaja, Global Head of Business Intelligence. “DataOps.live is exploiting every functionality Snowflake provides, bringing us the true DataOps practices we need. It enables our teams to create the data products we require, using all governance best practices like code check-in and check-outs, and allows multiple data engineers to work concurrently in the same team without creating a bottleneck or interfering with each other.”
Paul Rankin, Head of Data Platforms at Roche, adds: “Federating this approach across hundreds of developers in 20+ data product teams was the challenge… DataOps.live enables us to pull all this together in terms of orchestration, deployment, release management—and to do it at scale. It’s a complete game changer.”
Six Lessons Learned
“Many of the principles of creating data products for data mesh architecture have analogies in software development,” says Guy Adams, CTO, DataOps.live. “We can use those experiences to accelerate adoption. At the same time, we have already implemented data mesh with real-life customers that are now live. Some are huge, with many petabytes of data, and one customer has more than 30 different domains.”
Guy summarizes six key lessons learned:
1. Data Product Boundaries: the demarcation between product and user must be clear. “As with software, users of data products don’t need visibility of the ‘data internals’, but they do need to know their product will not suddenly change and is backward compatible in any case,” Guy says. “If a new version is needed, that has to interoperate with the previous version for a while.”
2. Don’t release too fast but frequently deploy: “I know of one organization which decided what it thought it needed from a particular data product, built it, released version 1, and within a week, the users said ‘this isn’t what we needed, it’s not fit for purpose’. By the end of the week, they’d released version 2, and were now committed to supporting two versions. Version 3 came within three weeks. They’d released a stable version far too early. It would have been better to release beta versions to users as a preview to gain feedback.”
3. Internal vs. external Data Products. Another pitfall is treating products for your domain differently from others. “There’s a risk that people may think, ‘Well, I have my internal users (who might be sitting next to me) who want data products, and I also have external users in other departments; life might be simpler if I treated internal products differently by, say, applying different and perhaps more relaxed requirements, fewer commitments to things like backward compatibility, and so on’. That’s a mistake in the real world.” Maintaining two different kinds of products means more complexity, and today’s internal product may well become tomorrow’s external product. You have to treat them with the same degree of rigor.
4. Allowing access to Data Product internals. “At some point, a user may say, ‘I need access to your Sales Forecast information. I know it’s in your database or Staging area. Can you give me SELECT access?’ In effect, they are asking for a backdoor. What you need to do is make it available through the Data Product layer, as you cannot allow backdoors. The second you make Data Internals part of, in effect, the Data Product, that becomes something you’re also committed to keeping, maintaining its stability. So you add Forecasts to your Data Product, and if you do it right, it can only take a few hours. It’s now a formally tracked part of the Data Product and not something you’re giving backdoor access to.”
5. Federated Governance and reuse. In software development, multiple teams building multiple applications draw on a central library of configuration, code, testing frameworks, reference data reusable code, and so on. This is the way to develop applications faster, that are more stable (bugs are fixed once and propagate everywhere), and more secure as governance and compliance are defined centrally and rolled out across all. “A strong DataOps framework means you can apply exactly the same approach to Data Products in a data mesh architecture,” Guys says. “This is critical for efficiency. It makes projects faster and development more disciplined. It’s what enables Federated Governance: you define your security principles in one place but informed by feedback from product teams.”
6. Derived or Secondary Data Products. “This concept is fairly common in the software world: people mixing application components and functionality behind adapted APIs: using published interfaces to create APIs that look like a single entity for the consumer but are, in fact, a composite of aggregated functionality,” Guy says. “We take exactly the same concept into the Data Product world, with a combination of ‘my’ data enriched with data from other products, but we only ever use the published product interface and never go back to the Data Internals. We are already seeing Data Products that are entirely composites of others.”
Business Value and Benefits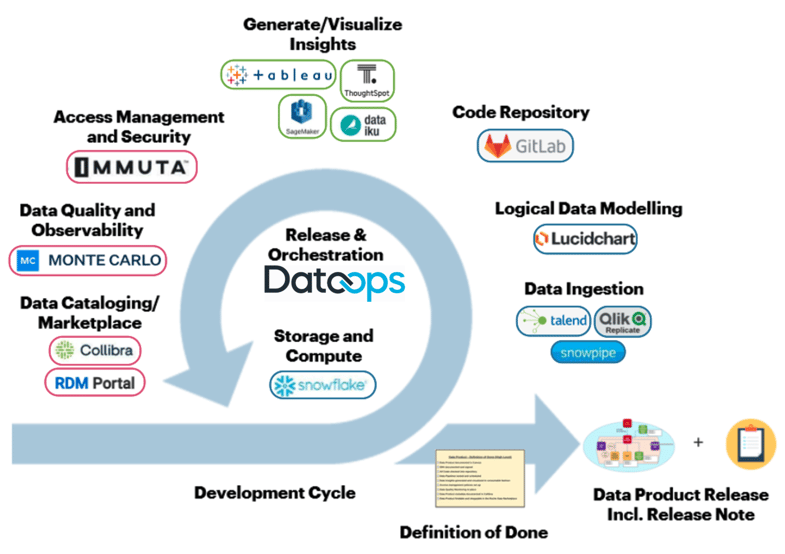 Source: Roche
Source: Roche
Roche has implemented a comprehensive technology platform in order to deliver on the promises of Data Mesh, including many best-of-breed solutions. In order to avoid the risk and integration nightmares of trying to get these disparate solutions to work together, Roche has leveraged the automation, orchestration, and release management capabilities delivered by the DataOps.live platform. Omar Khawaja explains, “DataOps has moved to the heart of everything we do”.
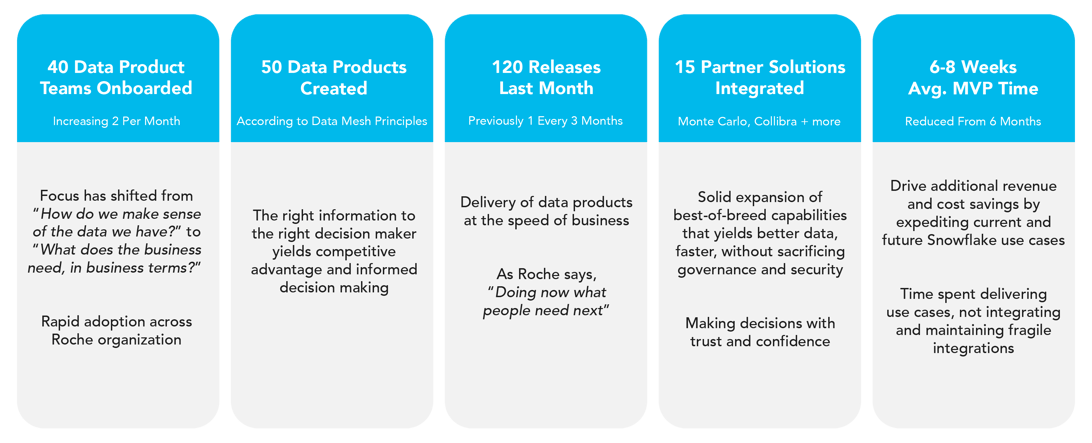
This approach has yielded dramatic results since beginning their platform build in February 2021:
Lessons Learned and Conclusions
There are three categories of best practices and lessons learned thus far from Roche Diagnostics’ journey.
The first of these is a careful consideration of the team structure—considering the distinct roles and responsibilities of a DataOps Engineer vs. those of both traditional Data Engineers and casual users. Care was given to ensure that each Product Team has a DataOps Engineer to provide focus and drive the overall process to the delivery of compelling Data Products.
Secondly, establishing a Center of Excellence (COE) in order to plan, deploy and maintain their platform and ecosystem effectively has been critical at Roche. Data Mesh and DataOps are relatively new concepts and, as we’ve discussed, represent a new approach to delivering Data Products that drive insight into superior decisions and outcomes. There’s also an appreciation for recognizing that perfection may be an aim but that there’s value in commencing rollout when the product is “good enough” and then further refining it later. This process is complemented by an emphasis on documentation and communication—both with and across teams and with a focus on enablement.
Last, the Roche team points out that it helps to select best-of-breed tech solutions that naturally work together. Building and maintaining custom integrations can be risky and come with a weighty Total Cost of Ownership when compared to approaches like DataOps.live, which leverages containers and standard API constructs to orchestrate data pipelines, observability, and the entire process detailed in the diagram above.
Implementing a robust functional data mesh architecture is both a technical shift and a cultural change; analytical data, its distribution, and its uses throughout the organization must evolve to fit this exciting model. As we’ve seen with DataOps.live customers, the benefits of data mesh are truly compelling, delivering Data Products in weeks, not months, and unmatched confidence to make better decisions.
Ready to get started?
Sign up for your free 14-day trial of DataOps.Live on Snowflake Partner Connect today!

.png?width=400&height=250&name=TrueDataOps%20website%20blog%20image%20(3).png)


