
 By
Doug 'The Data Guy' Needham
By
Doug 'The Data Guy' Needham

In this blog we will introduce the ability of the DataOps.live platform to automatically deploy security roles following Snowflake best practices for separation of duties.
Managing the security of your enrichment platform (Data Lake, Data Vault, Data Warehouse) is one of the key responsibilities of the Data Architect, Data Engineers, and Database Administrators.
Every time an orchestration is run that ingests new data and updates or creates a Data Product the data is at risk of having some permission changes that could cost the enterprise money, good will, or even customers.
Just do a Google search for Data Breach and you will see the various companies that have fallen victim of a mishap that released their customers data.
Kevin Mitnick once said: “Social engineering is using manipulation, influence and deception to get a person, a trusted insider within an organization, to comply with a request, and the request is usually to release information or to perform some sort of action item that benefits that attacker.”
Any slight misalignment between the design of a security architecture for an enrichment platform and the actual implementation could put your data at risk.
Using Snowflake as the database that lies at the heart of your enrichment platform is a fantastic way to ensure that your data is protected, available, and scalable. There are many components of security related to protecting a database. Network Policies, IAM roles, SSO integration, Multi Factor Authentication (MFA), and Key based authentication of users. In this article we will only be talking about the hierarchical implementation of roles with the database and giving users access to the correct role based on their business need to either read, ingest, or transform the data.
The online documentation about Snowflake security is extensive. By default, a data architect has the following roles to start with:
|
ACCOUNTADMIN |
Top-level role in the system. Owns the Snowflake account and can operate on all objects |
|
SECURITYADMIN |
Security Administrator: Can watch and manage users and roles. Can also change or revoke any grant |
|
SYSADMIN |
System Administrator: Has privileges to create warehouses, databases, and other objects, and grant those same privileges to custom roles |
|
USERADMIN |
User and Role Administrator: Can create users and roles in your account and grant those same privileges to other custom roles |
|
PUBLIC |
Pseudo-role that is automatically granted to every user and every role in your account |
These are the most fundamental functional roles provided by Snowflake.
One of the recommendations from Snowflake is that following an approach of Role-based Access Architecture allows fine-grained least access. How does this work?
A system role is defined for your overall Enrichment Platform. This role is a child role of the SYSADMIN role. In other words, someone using the SYSADMIN role can do all the things that the system role can do.
Domain roles are defined to define the business function that a role is performing. For example: Data Loader, Data Scientist, Data Analyst, Reporting.
Functional roles act to tie things together. The access roles defined next are assigned to the functional roles. The Functional roles are the children of the domain roles to segregate functionality, and the users are assigned to functional roles (Data Scientist, Business Intelligence User, Data Engineer) depending on their business need.
Database Objects are assigned access roles with certain privileges: Select, Insert, Update, etc....
This starts to sound complicated, and it could be. This diagram stands for how these roles should be implemented.
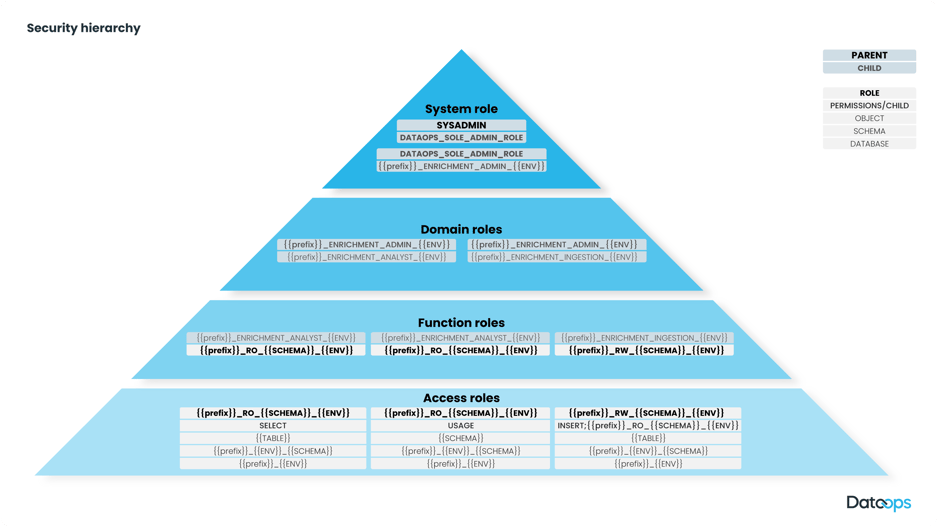
With DataOps.live these roles can be defined in configuration files. Every time the pipeline file runs an orchestration the part of the DataOps platform called the Snowflake Object Lifecycle Engine (SOLE) will compare what is implemented in the database it is working with (Production, Development, Quality Assurance, or Feature Branch databases) to the configuration files to decide if there are any changes that need to be made. SOLE treats the configuration file as the source of truth.
If a bad actor has created a new role and granted that role permission to read from some critical tables, SOLE will see that this ROLE is not defined in the configuration file. It will remove that grant and restore the grants back to the way the configuration file specified.
The details of how SOLE does this are beyond the scope of this article, by we will talk about the configuration files.
Before jumping into what a configuration file looks like, there is a quick aside we must cover. The DataOps.live platform includes support for the Jinja template language. Jinja is a text-based template language that can be used to generate the text within the configuration files. These files in the DataOps platform have the middle work template in them (e.g., databases.template.yml, roles.template.yml)
There are multiple ways to set up the configuration files.
They can be hardcoded every time they are needed. For more info on in our documentation, see hardcoded grants.

They can be set as variables to use throughout the configuration files so that the roles are only defined in a unique location.

They can be set as dynamically created variables and generated at orchestration time-based on human readable configuration files. (Writing code that writes code).

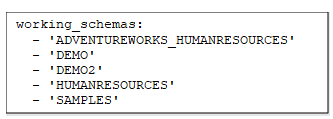
This part of the Jinja code will read from three files (working_schemas.yml, access_roles_reader.yml, and access_roles_writer.yml)
working_schemas.yml
access_roles_reader.yml

access_roles_writer.yml

Since the space for this jinja code is limited, I will walk through it.
First, we have a loop that creates variables for every schema defined in working_schemas.yml. We can look at just one above in the example showing how to set a variable to use such that the roles are only defined in a unique location (dflt_schema_grants_DEMO).
Second, we set the variable up to apply the permission USAGE of the schema to all the reader roles in the access_roles_reader.yml file.
Third, we set up MODIFY of the schema to all the writer roles in the access_roles_writer.yml file.
Finally for the schema variable, we iterate through the CREATE FUNCTION, CREATE VIEW, and CREATE TABLE permissions for the writer roles in the access_roles_writer.yml file.
The next variable we are setting (dflt_table_grants_DEMO) can be applied to all the tables in the DEMO schema.
Select is granted to the reader roles.
Insert, Update, Delete, and Truncate are all granted to the writer roles.
What is the advantage to this approach?
An Enrichment Platform no matter your choice of implementation will continue to grow. New sources, new data products, new users, new questions, and new use-cases will come up. As this grows just add the new schemas to the working_schemas.yml file. If there are new reader access roles or writer access roles, these can be set up in the basic yaml files that specify reader or writer access roles.
One other step in this process is to define the roles and assign the access roles to the functional roles. The following bit of jinja iterates through the defined variable files and builds out the hierarchy by creating the child role, then assigning the child role to the parent role.
roles.template.yml

Again, using simple configuration files as input to this process allows all the required grants to be generated based on definitions of what roles need to be defined and used in the right places.
We covered a few ways to set up the configuration files for SOLE to implement the security hierarchy designed by the Architects. Hardcoding values, creating variables to apply to various classes of objects within Snowflake, and finally dynamically generating the configurations using Jinja and some variable files. Regardless of how the configurations are set up SOLE will take an observation of what is implemented in the database and compare that to what the configuration file says. If there are any differences between what is observed and what is specified, SOLE will conform the Snowflake Security hierarchy to what is specified.
SOLE can do this every time it runs.
Verifying the security that is deployed matches what is designed and stored in the platform git repository. Every time.
This is Automation at its finest. Wouldn’t you sleep better knowing this automatically verifies security at every run?
There are a few other pieces to this set up that I have not covered here, like assigning users to roles, that topic will have to come later. Rest assured it is all done via configuration files, jinja scripts and SOLE doing the implementation.
There are many more things that can be done with this jinja capability that will enable you to be able to turn requests around and deploy things to production faster than ever before.
If you want to learn more about how DataOps.live can enable the automation of your Snowflake environment, check out our pioneering approach to DataOps and sign up for a free 14-day trial of DataOps.live. Also don't miss us at Snowflake BUILD—The Data Cloud Dev Summit where DataOps.live will have a session on Wednesday, November 16th at 3:30pm EST! Click here to register.
How can we help you?



