
Accelerate your data engineering with the Dynamic Suite™
Bring software engineering rigor to your data pipelines.
DataOps.live helps teams build, test, and ship trustworthy
data products — faster, safer, and at scale.
Data product engineering tools for trustworthy insights
Data environments are messy: growing data, shifting sources, evolving infrastructure. But your business still expects answers it can trust.
DataOps.live's Dynamic Suite of data engineering accelerators helps data teams deliver insights as a reliable, governed, and secure service by turning data projects into true data products.

Dynamic Delivery (CI/CD) for Snowflake
Take database objects to production in minutes. Dynamic Delivery from DataOps.live upgrades your CI/CD pipeline with automated schema design, testing, and governance.
- Design and develop schema objects safely and seamlessly.
- Control, audit, and secure every deployment.
- Validate changes across environments with automation.

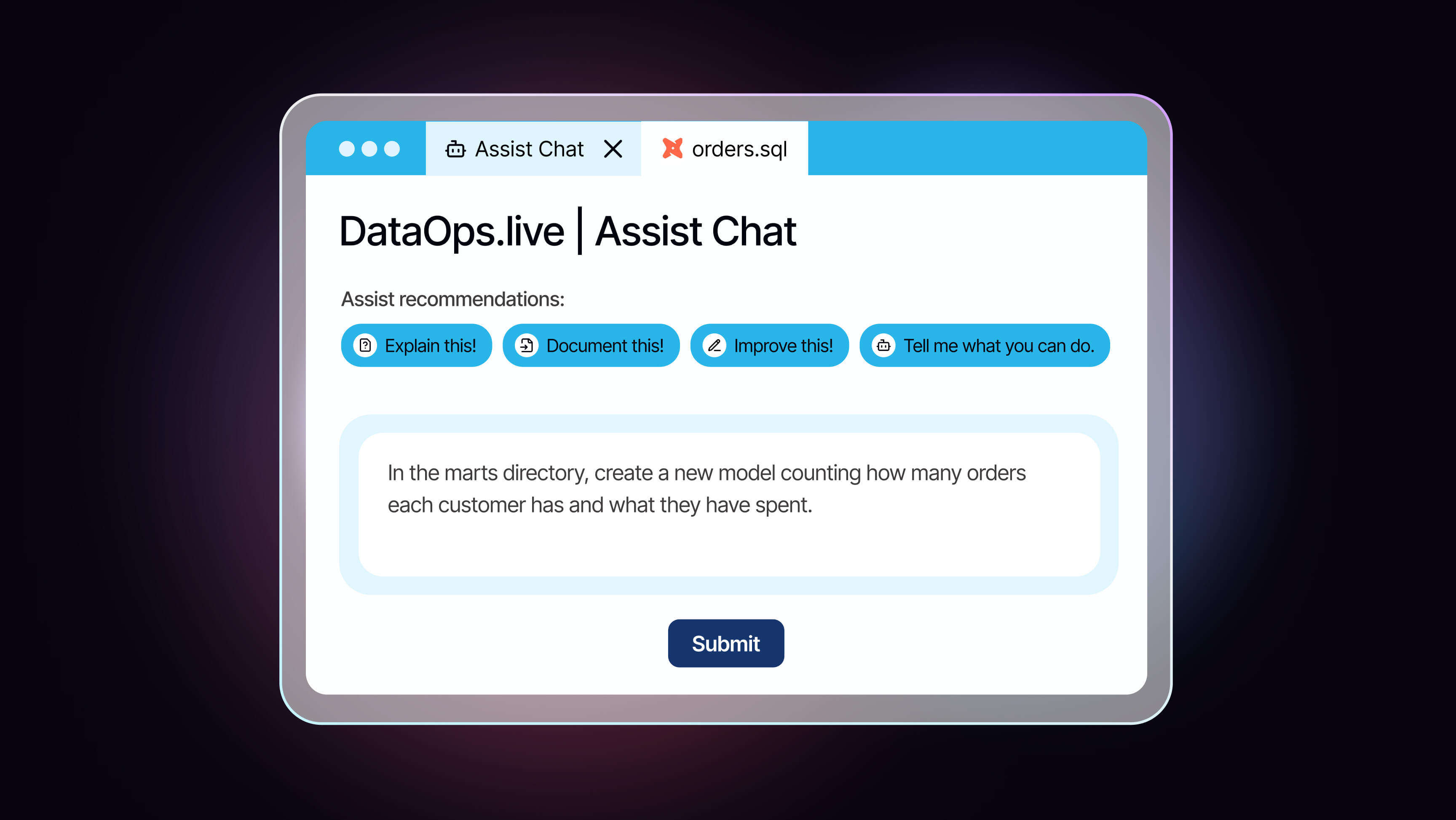
Dynamic Transformation for dbt™ for Snowflake
Spend less time writing SQL scripts and more building data products that drive trusted insights. Dynamic Transformation from DataOps.live streamlines development, deployment, and environment management across the dbt™ lifecycle.
- Automate dbt™ projects with templates and AI guidance.
- Ensure governance with visibility across teams and environments.
- Test transformations with technical and business quality checks.
If there is one tool that will change your life forever, it is Dataops.live. Go and see for yourself, as this is the heart of your modern data stack!
”/Paul%20Rankin.png?width=140&height=140&name=Paul%20Rankin.png)
/Roche%20logo.png?width=150&height=81&name=Roche%20logo.png)
DataOps.live delivered in a massive, massive way, and we couldn't imagine where we'd be now without their partnership.
”/Vernon%20Percival%20Tan.png?width=140&height=140&name=Vernon%20Percival%20Tan.png)
DataOps.live is a great choice for companies that need orchestration for complex data pipelines around Snowflake.
”/Wayne%20Eckerson.png?width=140&height=140&name=Wayne%20Eckerson.png)
/Eckerson%20Group%20logo.png?width=194&height=54&name=Eckerson%20Group%20logo.png)
DataOps.live continues to be a true partner, supporting OneWeb’s continuous rollout of data products across the organization for the benefit of our customers.
”/Miguel%20Morgado.png?width=140&height=140&name=Miguel%20Morgado.png)
/OneWeb%20logo.png?width=222&height=70&name=OneWeb%20logo.png)
DataOps.live is about collaborative development, it’s about the ability to coordinate and automate testing and deployment and therefore shorten the time to value.
”/Mike%20Ferguson.png?width=140&height=140&name=Mike%20Ferguson.png)
/Intelligent%20Business%20Strategies%20logo.png?width=150&height=50&name=Intelligent%20Business%20Strategies%20logo.png)
Try our free Snowflake
Native Apps
Get started with Dynamic Delivery or Dynamic Transformation. No extra infrastructure. No setup. Just 500 minutes monthly—free, forever.
