
 By
Thomas Steinborn, SVP Products
By
Thomas Steinborn, SVP Products

With the Fall 2022 release of DataOps.live, organizations can now execute DataOps and Data Engineering activities at Scale, handling greater complexity and more data pipelines with an even higher degree of automation.
The new release combines a unified developer experience with the ability to perform DataOps at Scale: enhancing the day-to-day experience and enhancing the operation of data workloads. It includes a new safety net for development teams and new security measures. As we work to become the industry standard for enterprise teams to automate, orchestrate, observe, and deploy cloud data platforms, our Fall 2022 release doubles down on that promise.
This means handling more data domains at the same time, creating more Data Products at the same time, and building larger and more sophisticated Data Products at the same time—while data engineers are 100% in control. We call this No-Fear Data Engineering at Scale, and we believe it’s unique to the DataOps.live platform, accelerating productivity and further reducing time-to-value.
DataOps at scale powered by a unified developer experience
The Fall ’22 Release provides a more natural, streamlined experience for individuals and teams. DataOps.live has preannounced the private preview for its fully Integrated Development Environment (IDE) and its Data Product infrastructure as a code:
- Existing and new DataOps Developers can now access a fully hosted IDE, very similar to Visual Studio, with all the pre-packaged components and plugins needed for a highly efficient Snowflake development experience. Data Products developers can now code much faster with all the standard IDE functionality like auto-completion, and immediately test every change as they make those changes (no waiting for minutes for pipelines to run). Day-to-day developer productivity can increase by up to 50% depending on the amount of development time they are spending every day
- New DataOps Developers have a shorter and more effective learning curve as Snowflake infrastructure as code and data modeling project layout use the same concept
- Data Product Owners organize projects by Data Product and dataset
- Data Engineers find the one table they need to work among thousands and experience fewer merge conflicts in their code
- The Fall ’22 Release also delivers the Snowflake Object Lifecycle Engine (SOLE) configuration generator, supporting lift & shift initiatives to Snowflake. Whether starting a new DataOps project from an existing Snowflake account or adding additional datasets to an existing project, onboarding times are reduced by a factor of ten. Additionally, table definitions for your ingestion layer are now shared between the SOLE configuration and the Modeling and Transformation Engine (MATE) data sources. We eliminated steps and removed manual effort, thereby enabling DataOps developers and data engineers alike to be even more productive. You can now quickly increase the number of developers you support, moving from tens to many hundreds, with the necessary organization and controls in place. DataOps.live customers such as Roche Diagnostics are already scaling up rapidly with over 40 domain teams and thousands of end users
DataOps at Scale powered by Kubernetes
The DataOps Runner and Orchestrators on Kubernetes now enable customers to dynamically scale their enterprise DataOps infrastructure within their highly managed, highly available cloud architecture while using compute resources more efficiently and reducing cost. Load balance all your workloads across nodes, and let Kubernetes ensure high availability for all your data pipelines.
Deploying the Runner and Orchestrators on Azure Kubernetes Service (AKS) or AWS Elastic Kubernetes Service (EKS) minimizes operational overhead and reduces infrastructure costs by consolidating workloads across domains and Data Products on a Kubernetes cluster. We’ve removed limits from delivering more complex Data Products faster and at lower cost, using better resources.
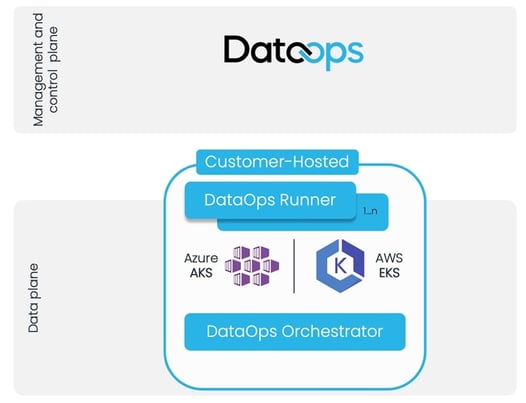
Figure 1–DataOps.live support for Kubernetes enables easy, rapid scaling to support very large Data Products with more than 1,000 Snowflake Objects
A new safety net for developers
Human error, temporary resource failures, and similar incidents have occurred in the past and will happen in the future. Such incidents must not lead to data loss. Putting DataOps engineers in full control, the Fall ’22 Release adds Snowflake Object Deletion Prevention, making each deletion an explicit user-defined action. This is yet another way the DataOps.live platform enhances developer productivity and ensures new starters can fail fast, and in turn, contribute fast without any interruptions.
Additional security: Support for HashiCorp Vault
The new release also brings a valuable addition to the Secrets Manager, a core capability of the DataOps.live platform for securing, storing, and controlling access to credentials. HashiCorp Vault is included as a new enterprise credentials manager next to AWS Secrets Manager, AWS Systems Manager Parameter Store, and Azure Key Vault.
‘Pipelines don’t stop, jobs keep running’
Another step towards zero downtime of particular interest to operations and infrastructure teams, the new release ensures data pipelines do not fail during scheduled maintenance. Jobs in progress complete and wait until DataOps.live is available. Once available, the jobs send back status, logs, and other information. The next job involving the pipeline starts normally once the maintenance is finished.
All in all, this exciting release raises the bar in team-based DataOps development and control—with developers benefitting from the security they expect from the leading enterprise DataOps platform—DataOps.live.
To learn more and get started, check out our pioneering approach to DataOps, read the detailed Roche case study, and sign up for a free 14-day trial of DataOps.live
Also, don’t miss our session at Snowflake BUILD on Wednesday, November 16th, from 12:30 to 1pm PST! Click here to register.

.png?width=400&height=250&name=PR%20MOMENTUM%20(1).png)

