
 By
DataOps.live
By
DataOps.live

Most data teams are expected to power AI with data they don’t fully trust. Pipelines are manual, testing is inconsistent, and delivery slows under scale. DataOps addresses this by applying software engineering practices to how teams build, test, deploy, and manage data products and data applications. By combining automation, CI/CD, testing, and governance, DataOps increases data reliability and reduces time to value for data products.
DataOps helps organizations achieve a successful data operation with accurate insights. Data Operations teams create business value from data by working more efficiently with data. DataOps also allows for better collaboration with business stakeholders. This efficiency comes from DataOps’ foundations in DevOps, Agile, and Lean manufacturing principles.
Jump to a DataOps topic
-
What is DataOps vs. DevOps?
-
How DataOps works (what is DataOps changing?)
-
Why modern organizations need DataOps?
-
The benefits of DataOps
-
Follow #TrueDataOps for even more benefits
-
Four important roles for a DataOps team
-
How to get started on your DataOps journey?
What is DataOps vs. DevOps?
Before we start comparing, let’s define DevOps.
DevOps (development and operations) is a philosophy and practice that combines software development and operations functions. It aims to shorten time to value by reducing the software application development and deployment lifecycle and providing continuous delivery and high software application quality.
After the success of DevOps, data operation philosophy borrowed operations principles like CI/CD and adapted them for the data world. With Data “Ops” engineers building data products could establish more efficient practices for their own workflows. Highlighting the similarities and differences between DevOps and DataOps will help define both further.
What DataOps and DevOps have in common
Because DataOps evolved from DevOps, data teams that adopt DataOps principles bear some resemblance to software teams in processes, culture, and technology.
Table: Similarities between DataOps and DevOps
|
Similarities |
DataOps and DevOps |
|
Processes |
Both use Agile methodology and focus on automation and continuous improvement, including using continuous integration/continuous delivery (CI/CD). |
|
Culture |
Both require a culture shift that involves breaking down silos between teams/functions and collaborating to deliver value. |
|
Technology |
Both rely on modern tools to automate and optimize every part of the development, testing, delivery, and management process. |
How data operation is different: DataOps vs DevOps
While deployment is the end of the line for DevOps, data operations are a different story. Data products deliver data continuously, requiring ongoing monitoring,
Unlike DevOps, data teams are not just developers and technical experts. They also include non-technical members including data product owners, data stewards, business stakeholders, and end-users.
Table: Differences between DataOps and DevOps
|
Differences |
DataOps |
DevOps |
|
Processes |
Build or update data products that continuously deliver quality data to end users. |
Build or update software applications to deliver functionality to end users. |
|
Culture |
Data operations teams are both technical (DataOps developers, data engineers, and data scientists) and non-technical (data product owners, data stewards, business stakeholders, and end-user). |
Software teams are primarily technical (software engineers, IT operations teams). |
|
Technology |
Requires constant monitoring and updates due to the ever-changing nature of data sources, data, and use cases. |
Updated on a defined, repeatable schedule. |
How DataOps works (what is DataOps changing?)
DataOps is an approach that incorporates agility and governance into enterprise data delivery. The balance of agility and governance is integral to the DataOps philosophy and method and enhances collaboration between developers and stakeholders.
The ability to respond promptly to user demands while remaining true to governance principles like change control, accountability, data quality, and data security is critical to any data operations project. Continuous, incremental development, testing, and delivery lead to an accelerated data lifecycle that increases end-user satisfaction while reducing overall development costs.
In contrast to the plan-first, develop-later methodology (the waterfall method), changes to data products and platforms are made during development based on the collaborative and continuous feedback of the stakeholders, as well as automated testing and monitoring.
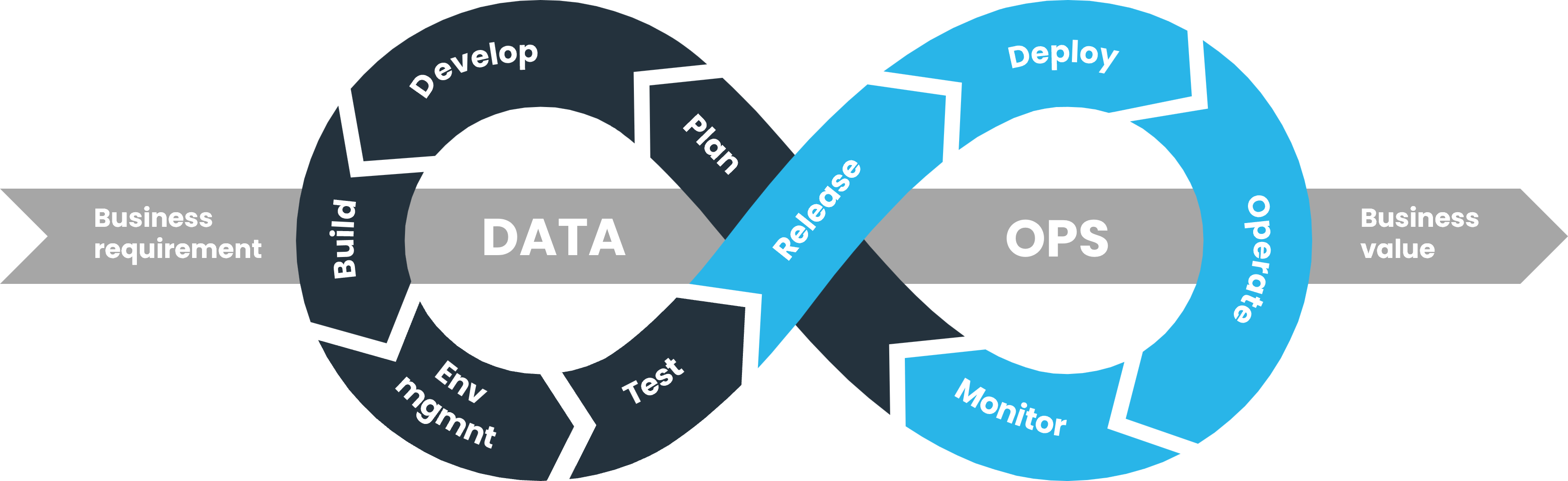
Continuous development is at the heart of DataOps
Why modern organizations need DataOps
Data is now essential to the success of every organization. In their quest to stay competitive, business data consumers need and expect same-day—or real-time—data delivery to aid in data-driven decision-making. Continuous data is also crucial in the mad rush to artificial intelligence (AI).
At the same time, data today is larger (volume), faster (velocity), and more diverse (variety) than ever. Data sources live inside and outside the organization, in the cloud and on-premises, in modern and legacy systems. Data infrastructure and technologies like cloud, mobile, edge computing, and AI constantly evolve.
Keeping up with high end-user expectations and constantly changing data and infrastructure are just the start of the challenges data teams face.
Data Team challenges you can solve with DataOps
As they build, deploy, and manage data products, data professionals encounter other issues when they don’t have a DataOps practice.
Challenge: Demand always outstrips capacity
Because data is so critical to every part of a modern organization, data teams are perpetual bottlenecks overrun with data requests. They can never keep up with mile-long backlogs of requests from business users.
Challenge: Outdated processes and technologies
Since building integration jobs, testing and retesting jobs, assembling analytics pipelines, managing dev/test/production environments, and maintaining documentation are so manual, they are also slow and prone to error.
Any change early on (e.g., data source, number format) can lead to brittle data pipelines breaking often, piling onto the already overwhelming amount of data engineering work. Even worse, it can lead to bad data downstream, causing data consumers to lose trust in the data delivered. Data teams’ challenges largely boil down to a lack of agility.
Solution: Agile makes all the difference for data teams
The Agile development method has proven to be a superior process that yields faster and more dependable code and pipeline releases, driving increased speed and reliability of data analytics.
DataOps enables data engineers and data stewards to be agile by focusing on reuse rather than reinvention and adding automation wherever possible. Being agile frees data team members from time-consuming and repetitive tasks.
Organizational challenges
The main challenges organizations face when they don’t use DataOps lie in data governance. Problems arise when many team members and business owners are asked to govern and observe many data products (or do so without being asked).
Challenge: Business teams go around data teams
When data teams are slow to deliver the insights business users need, business teams start to get nervous. With so many easy-to-use tools out there and more data savvy, they’ve begun spinning up their own self-service tools and creating their own datasets, sidestepping IT and data teams altogether.
The business ends up with copies of the same fundamental datasets (for example, customer information), prepared by different teams, with different results—and no idea which to trust. It’s a data governance nightmare! And for more than quality.
Challenge: Compliance is constantly evolving
Data regulations are continually being added and evolving (GDPR, CCPA). As a result, data teams have to be prepared to account for how they acquire, transfer, store, process, and use data. Those ungoverned business-owned datasets can quickly run afoul of regulations, leading to potential privacy violations, regulatory violations and fines, and reputational damage.
To overcome these challenges, organizations need repeatable processes that scale throughout the organization, from one team to dozens of teams.
Solution: Federated governance
Organizations must answer questions about delegating ownership to data product owners, data trust, and ensuring unbiased decisions and ethical behavior.
To keep an organization agile, the best governance model is federated. Federated governance is when data governance policies are defined centrally and domain teams have some flexibility in how they execute the policies based on what works best for their environment. Often, the data governance leader is centralized with data stewards in each business domain team. This enables business stakeholders and data product owners alike to exercise control throughout the organization.
Federated governance can also be embedded in data pipelines and supplies the rules, processes, and procedures that maintain data security, quality, and deliverability. Data may be stored in a central repository, like a data warehouse or data lake, for processing. However, federated governance is a critical component of data mesh or data fabric, which promotes decentralized data architecture.
.png?width=1000&height=600&name=Join%20today%20(1).png)
The benefits of DataOps
What is DataOps doing for companies and data engineering teams like yours? While the primary outcome of DataOps is getting more business value from big data faster, DataOps delivers many benefits on the way. DataOps:
- Lets data teams deliver reliable and continuous data through automation and Agile methodologies.
- Enhances collaboration and lets you do more with technology—using DataOps we’ve seen a data team of four people complete 200 cycles, 80 commits, and 50 pushes to production in 1 day!
- Improves data quality and lets you provide business stakeholders with data assurance/guarantees. In turn, data consumers trust data and stop going around IT/data teams.
- Lets business and data teams work more collaboratively for better outcomes.
- Minimizes risk to your overall data platform by ensuring governance.
- Lowers the cost of your data platform by providing guided insights to your data pipelines.
- Shortens data product production time, reducing implementation costs by more than 70%.
- Streamlines maintenance of code which can reduce the TCO of data products by over 60%.
Follow #TrueDataOps for even more benefits
#TrueDataOps is a philosophy that defines how to implement an effective DataOps methodology. It focuses on value-led development of data pipelines, for example, to reduce fraud, improve customer experience, increase uptake, and identify opportunities.
We can sum up #TrueDataOps in seven pillars. Let’s look at a few of them:
Extract, load, transform (ELT and the spirit of ELT): ELT—an alternative to traditional ETL where data transformation takes place before you load it—stores raw data in the data lake. This approach builds for a future you can’t yet imagine by keeping all the original information intact. It lets you pull critical information from data without irrevocably altering it.
CI/CD (including Orchestration): Repeatable and orchestrated data pipelines for building and deploying everything data. It makes it easy to configure and release code, but you can also roll it back if a change is needed.
Component design and maintainability: Lets you use code more effectively—and saves time and errors—by reducing it to small, reusable components.
Environment management: Great environment management requires all environments to be built, changed, and (where relevant) destroyed automatically. It also requires a fast way of making a new environment look just like production. In a nutshell, you’re branching data environments the same way you branch code.
The four most important roles for a DataOps team
What is DataOps going to look like at your organization? When you build your DataOps team, there are four roles you should think about hiring.
#1 Data operation team role: Data Engineer
Data engineers perform crucial initial steps, such as migrating data from business applications. These can include, for example, customer relationship management (CRM) or human resources systems. Data is moved to the data platform, and the data engineer develops the code to transform raw data and populate schemas within the data platform. Data engineers also understand test-driven development principles and help design and implement tests to assure data quality.
#2 Data operation team role: Data Scientist
Data scientists create algorithms that solve problems by creating unique data combinations and working with data to provide forward-looking insights. Data science is a multi-disciplinary field most associated with data mining of big data and using AI and machine learning (ML) to glean new insights from distributed and massive data sets, often to produce predictions about the future.
#3 Data operation team role: DataOps Engineers
Like any Ops specialist, Data Ops engineers understand and apply the principles of DataOps to a data product. A team’s DataOps engineer has a broad understanding of DevOps principles like Agile development, data orchestration in a DataOps environment, and the tools used to automate processes in the data pipeline.
It may be possible to combine the skills of the DataOps engineer with other skills on the team, eliminating the need for a specific role as a Data Ops engineer.
#4 Data operation team role: Data Product Owners
Data product owners maintain the roadmap for each data product, from the inception of a new product through maturing and bringing it to broader adoption to finally sunsetting it when not needed. They further collaborate with business stakeholders and data stewards for requirements and discovery sessions.
How to get started on your DataOps journey
Data has become an essential resource for organizations of all sorts to develop new game-changing products and services, tailor their marketing to customers in a personalized way, and scale their businesses without the huge capital outlays required in years gone by.
But the teams responsible for harnessing the power of that data achieve those goals only if they have an effective process to do so. DataOps, and #TrueDataOps provides that process.
DataOps.live helps you start your DataOps journey quickly by providing Snowflake environment management, end-to-end orchestration, CI/CD, automated testing & observability, and code management wrapped in an elegant developer interface.
For faster development, parallel collaboration, developer efficiencies, data assurance, simplified orchestration, and (data) product lifecycle management, operationalize DataOps with the DataOps automation platform built for AI-ready data at enterprise scale.
/banner-green.svg)
Automate DataOps today.
Try DataOps.live free for 30 days.



