DataOps Resources

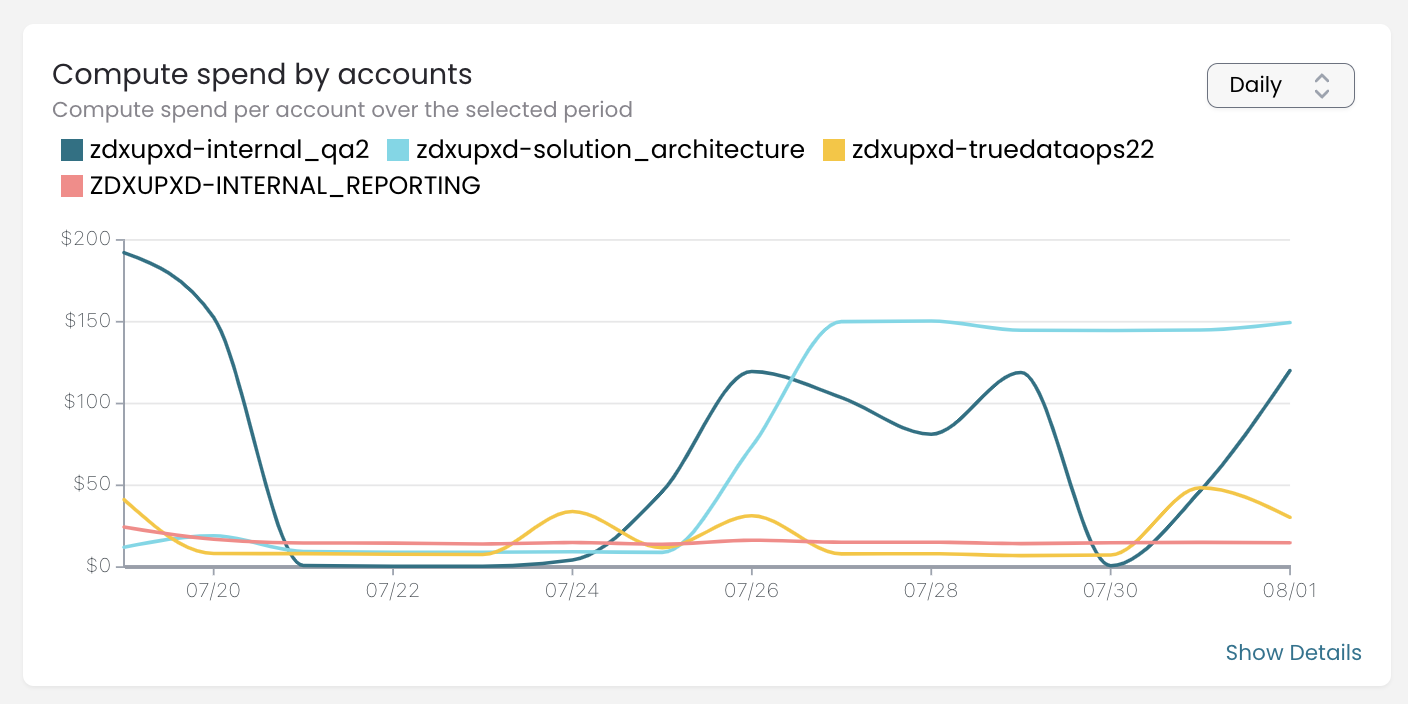
Manage your Snowflake spend in <10 mins per week using Spendview
Optimize your Snowflake costs in under 10 minutes per week with DataOps.live Spendview. Monitor multiple instances, cut...

Fall 2023 Product Launch
DataOps.live Fall 23' Product Launch is on here. Introducing DataOps.live Assist, your copilot for our Data Product...

Data Products Done Right: The New Way to Deliver Data Value
Discover how Data Productization addresses the challenges of data insights, access, and quality, and get insights from...

Data Products: Semantic Data Quality with DQLabs
Explore the evolving landscape of Data Mesh and data products with DataOps.live & DQLabs. Learn how to manage...

SecuPi Data Security and DataOps.live: Safeguarding your Finances
Discover how Dataops.live and SecuPi's partnership enhances Snowflake cost optimization and data security, preventing...

#TrueDataOps Podcast Series Returns with Season 2, Featuring In-Depth Technical Insights from Data Industry Thought Leaders
Following a remarkable inaugural season that featured 18 noteworthy guests and amassed over 10,000 views, Season 2 is...

Empowering Snowflake Data Cloud: Balancing Power, Costs & Efficiency
Unleash Snowflake Data Cloud's potential while managing costs efficiently. Explore insights and tools for optimization...

Introducing "Data Products for Dummies": A Comprehensive Guide to the New Model for Managing Your Data Assets
DataOps.live's "Data Products for Dummies" is set to become the definitive guide for individuals and businesses seeking...

Optimize Your Snowflake Spend
Learn how Spendview and Snoptimizer can help optimize your budget by identifying and automating optimization best...

Celebrating Season 1 and surpassing 10,000 listens of the #TrueDataOps Podcast!
Season 1 of The #TrueDataOps Podcast wraps with 10,000 listens! Join us in celebrating the success and stay tuned for...

Data Products Done Right
Unlock the potential of data with our Data Products Done Right Webinar. Learn how to turn data into an asset, manage...

What is a Data Product?
Data products done right. What are data products? Why do you need data products? What are the ten principles for data...
What is DataOps
Confused by all the DataOps info out there? Find out what is Data Operations, how it works, why modern organizations...

Unleashing Data Product Management and Observability
DataOps.live recently unveiled two groundbreaking features: Data Product Management and Comprehensive Observability....

DataOps.live Introduces Data Product Management and Observability
"Getting the most from Snowflake is a priority for our customers," says Thomas Steinborn, VP of Products. "Spendview is...