DataOps News


Becoming a modern Data company in 2024: continuous coaching with a solutions mindset
Discover how EON Collective empowered a leading healthcare company to revolutionize its data strategy, driving better...

DataOps.live further strengthens its partnership with Snowflake—achieves Elite Tier Partner Status and Technology Ready Validation
DataOps.live is now an Elite Tier partner of Snowflake, recognized for excellence in automating data products on the...

How DataOps helped me reach new heights in Developer Productivity
CTO Guy Adams shares a shocking productivity gap that led to DataOps.live. Learn about data products, a trend toward...

Data Products Done Right: delivering value now
DataOps.live launched a new book, Data Products for Dummies, at Big Data LDN late last year. The book’s authors and...

Build vs Buy Video
Do you Build or Buy a DataOps platform? Learn how DataOps.Live is helping organizations automate, build, and integrate...

OneWeb: Satellite providers goes stellar in six weeks with DataOps.live platform, Snowflake and AWS
DataOps.live & Snowflake & AWS are enabling OneWeb to govern & automate every data pipeline while creating a powerful...

The making of the Snowflake Solution Center opportunity
Dive into how Snowflake embraced the DataOps.live platform to revolutionize their sales demonstrations, fostering...

DataOps.live to deliver a streamlined Data Management Process for Snowflake's Global Technical Sales Teams
Snowflake's collaboration with DataOps.live aims to boost Sales Engineers' efficiency, productivity, and value, says...

Introducing your co-pilot for data product management: DataOps.live Assist
Explore DataOps.live's Fall '23 release with AI-powered DataOps.live Assist, transforming data product management....

Accelerate your AI/ML journey
Building Better AI/ML Applications Faster in the Data Cloud with BlueCloud, DataOps.live, and AWS.
Unlocking the Future: Your Ultimate Guide to Data Products with 'Data Products For Dummies'
Discover the future of data with Data Products For Dummies – Learn how to build and deploy successful data products,...

Introducing DataOps.live Assist, the New AI-powered Copilot for the DataOps.live Data Product Platform
Unlock DataOps.live Assist: The AI-Powered Data Engineering Copilot. Join our Fall Release webinar to revolutionize...

Building Data Products on Snowflake Using Dataops
Discover how DataOps.live leverages Snowflake to efficiently develop, manage, and scale data products, illustrated...

Building Data Products on Snowflake Using DataOps
In this session, we profile how a major pharmaceutical research company was able to scale out to 50 data products in...
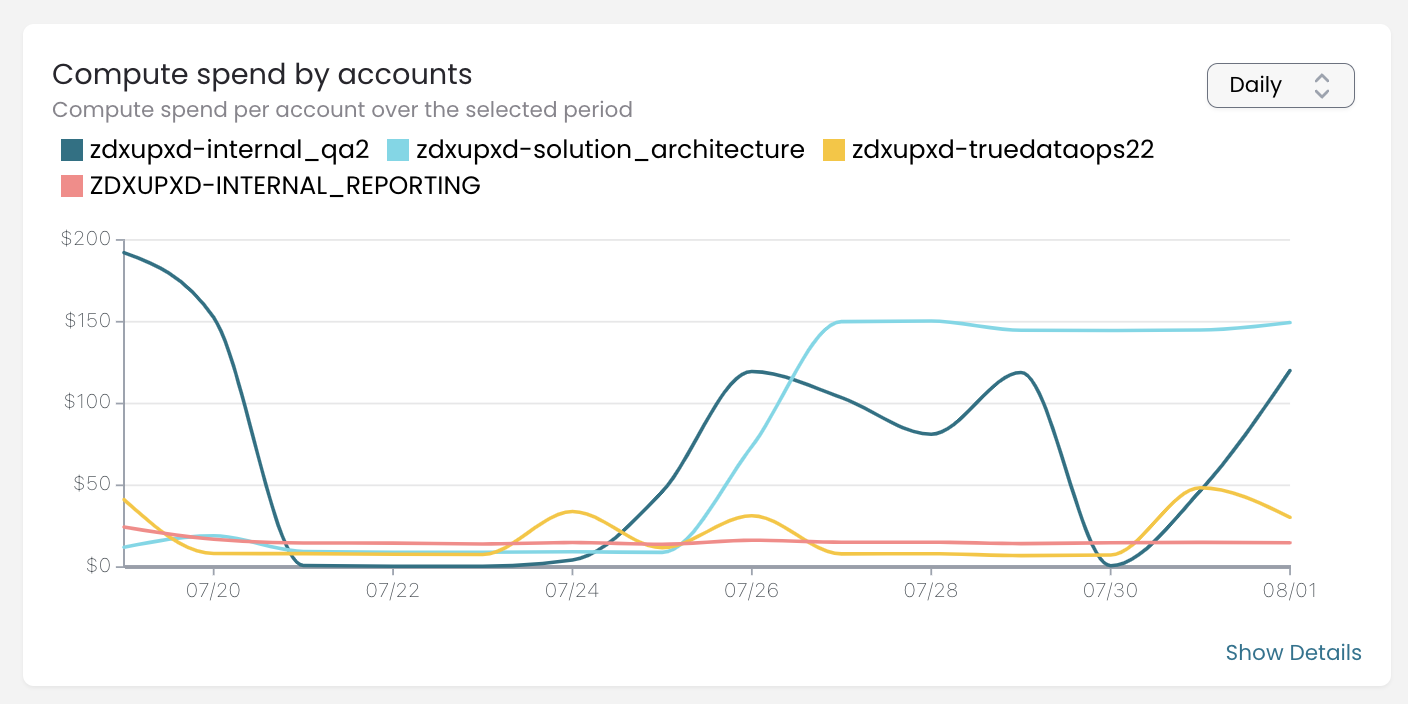
Manage your Snowflake spend in <10 mins per week using Spendview
Optimize your Snowflake costs in under 10 minutes per week with DataOps.live Spendview. Monitor multiple instances, cut...