
 By
Guy Adams - CTO, DataOps.live
By
Guy Adams - CTO, DataOps.live

This blog summarizes a discussion I recently had with Sanjeev Mohan on his podcast, It Depends. For the full conversation, including how generative AI works with DataOps and our relationship with Snowflake, watch It Depends #55. Then, continue learning with the ebook Sanjeev and I coauthored: Data Products for Dummies, or the original DataOps for Dummies.
I have a confession. While I’m the CTO and co-founder of DataOps.live, I didn’t start in data. In fact, I’m a relative newcomer to the space.
My background was 20 years in software engineering. But a little over five years ago, I became one of the first Snowflake customers in Europe. As soon as I saw what Snowflake made possible, I was hooked.
I made the leap to data, joining a small systems integrator (SI) called Datalytyx as their CTO. Suddenly, I found myself responsible for a team of data engineers, rather than software engineers. And after decades of leading highly efficient software engineering teams, I was shocked by what I saw.
The data engineering team had objectively terrible productivity. In fact, I worked out that my data engineers were about 70% less efficient than the software engineers I’d just left. I couldn’t accept it. When you’re talking about a team of 50 people at 70% less efficiency, these are big numbers.
It wasn’t a question of talent or ability, either. These were incredibly smart people, at the top of their field! So I wondered, why is this? What’s missing, and what could I do to bring those numbers up?
An epiphany about Engineering Efficiency
The biggest light-bulb moment came when we were working on project plans for big customers. The team would say, “We've got to put a month in the project plan to build a QA environment.”
In software engineering, I’d have been able to do that with the press of a button. Within seconds—maybe long enough to make a cup of coffee—I’d have had a clean, perfectly built sandbox. But in data engineering, building a testing environment for QA was a manual process that took a month. That was a big red flag for me.
The big difference, I realized, was the agility underpinned by DevOps. With DevOps, software engineers have a powerfully efficient process for continuous integration and continuous delivery (CI/CD).
I'd taken many organizations on the journey across Agile, DevOps, and CI/CD. I knew how powerful those principles could be, and I now saw the potential for applying them to the data space.
For our company to be more profitable and compete on cost, I wanted to make my data engineering teams dramatically more efficient. I wanted to make processes repeatable, more automated, and easier to support. I wanted standardization and better governance.
We looked to the best practices in software engineering. Then, we brought that agility, automation, and efficiency to the world of data management. Software engineering had DevOps; we began to develop the principles of DataOps.
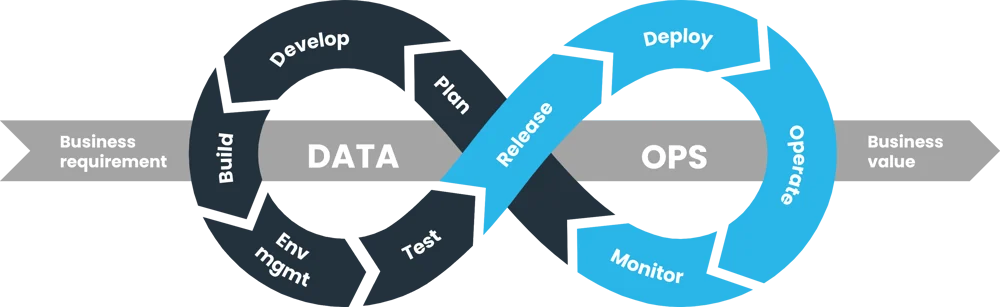
The DataOps Lifecycle
Like DevOps, DataOps is a set of principles, practices, and supporting technologies. But DataOps is more than just DevOps for data. In DataOps, these tools and processes work together to manage the complete data lifecycle.
The DataOps lifecycle includes the following core stages:
- Pre-development: Setting the foundation for a data project involves gathering requirements, defining objectives, and planning the development process (just like the product requirements phase in software development)
- Development: Building, testing, and maintaining data products, with emphasis on efficiency, automation, and iterative development
- Deployment: Releasing data products into production, including automated deployment, infrastructure management, and ensuring data quality and reliability
- Observability: Teams need to gather feedback, identify issues, and make improvements by monitoring, measuring, and validating data products' performance and effectiveness
- Iteration: Data products are continually improved and optimized through repetition of development and deployment cycles based on a user feedback loop
This is an iterative process, so the lifecycle loops back on itself in a continuous improvement cycle.
The move to Data Products
You may have noticed in the previous section, I talked about data as data products at each stage of the lifecycle.
Data Products, like software products, have well-defined objectives, costs, and values. They are managed, prioritized, and go through a development and deployment lifecycle. A data product can be anything from a real-time supply chain analytics tool to a dashboard for financial reporting.
Individual departments or teams within an organization can develop and maintain data products for their own use. Data products can also be monetized and sold externally. But a data product's value isn’t limited to its monetization potential. For example, a data product could deliver business value by finding new opportunities or flagging fraud.
Whatever they do, data products should deliver value to an end user with optimal efficiency and in alignment with business objectives.
Decentralization calls for reducing the technical barrier
One of the biggest shifts that we've seen recently, particularly in bigger organizations, is a move to decentralize data management. Instead of a central data engineering team managing everything, the responsibility for maintaining data products is evolving to the teams that actually understand the data.
There are several implications that come with that. One is maintaining centralized governance standards. Another is that all of a sudden, there are people who want to build data products, iterate on data products, and deploy data products who aren't data engineers.
We’ve been focusing on reducing that technical barrier. By adding wizard functionality—an actual data product builder—anyone can go from nothing to a deployed data product in 10 minutes or less.
The future of DataOps
My North Star for DataOps is parity with DevOps. I mean that in terms of capabilities and technical maturity, but also in adoption and understanding.
When Justin Mullen and I started DataOps.live, we were at zero. Today, I think we’re 60% of the way there. We’re well on our way in terms of awareness, but real-world adoption is still low. In two years’ time, I think we’ll be very nearly there.
I’ve seen DataOps.live customers reap enormous benefits from embracing the principles of #TrueDataOps, including:
- Faster Releases: Data teams following DataOps processes streamline development, and can deploy data products more quickly
- Faster Time to Business Value: By shortening development cycles with DataOps, organizations can accelerate the time to value for data products
- Cost Efficiency: Teams leveraging DataOps have tools and techniques to optimize resource usage, reduce waste, and improve overall cost efficiency in data management
- Improved Data Quality: Data teams following #TrueDataOps principles incorporate automated testing and validation, ensuring that data products are reliable, accurate, and trustworthy
- Efficiency at Scale: Organizations that follow DataOps processes gain the ability to operate more efficiently, even across multiple teams and in larger data engineering departments
Analysis across a set of DataOps.live customers showed that in 2023, we prevented 91,000 production failures due to poor data quality alone.
As all kinds of companies move toward becoming data companies, organizations are realizing the speed and efficiency of their data programs are stumbling blocks. They need to continually improve their data management processes or fall behind. DataOps is the way forward.



