
 By
DataOps.live
By
DataOps.live

The rapid and continued expansion of data systems and the exponential explosion of data drive the use cases for advanced data analytics and data science applications. However, without adopting the principles and philosophy of #TrueDataOps, it will always be challenging to develop, test, and deploy data pipelines that deliver trusted, reliable data to analytics applications and machine learning models in a short space of time and according to business stakeholder requirements.
The Gartner report titled "Gartner Top 10 Data and Analytics Trends for 2021” states that its seventh trend is data and analytics as its core business function. And its fifth trend lists DataOps as part of what it calls the "XOps" movement. Therefore, it stands to reason that implementing a DataOps model as the foundation for your data ecosystem is imperative. Let’s consider how #TrueDataOps will improve your DataOps pipelines, including CI/CD pipelines, to improve both the speed and quality of your data analytics.
What is #TrueDataOps in relation to DataOps?
As noted by Wayne Eckerson and echoed by us, “DataOps is an engineering methodology and set of practices designed for rapid, reliable, and repeatable delivery of production-ready data and operations-ready analytics and data science models.”
The #TrueDataOps philosophy, while focusing on the principles and practice of DataOps, takes a step back and looks to the "truest principles of DevOps" as its foundation.
As quoted by TrueDataOps.org, “the tension between governance and agility is the biggest risk to the achievement of value.” As a result, “our belief—and experience— indicates that technology has evolved to the point where governance and agility can be combined to deliver sustainable development by #TrueDataOps.”
Because of the imperative of adopting the #TrueDataOps philosophy as part of your data ecosystem, let’s take a quick look at its benefits, as illustrated in the following diagram:

Using CI/CD to deliver value to the data pipeline architecture
There are several subtle differences between the data pipeline and CI/CD constructs.
The data pipeline architecture forms an integral part of a robust data platform (such as DataOps.live) and is used to ELT (Extract, Load, and Transform) data from its source and load the transformed data into its destination, including data analytics applications and machine learning models.
On the other hand, CI/CD (continuous integration and continuous delivery) is a DevOps, and subsequently a #TrueDataOps, best practice for delivering code changes more frequently and reliably.
As illustrated by the diagram below, the green vertical upward-moving arrows indicate CI or continuous integration. And the CD or continuous deployment is depicted by the blue horizontal arrows. In summary, the DataOps pipeline is similar to the CD in the CI/CD architecture. And the most significant difference between CI/CD for DevOps and DataOps is how software products and data products are deployed.
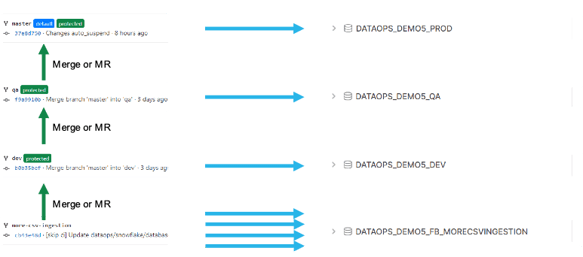
And in the DataOps world, CI/CD pipelines are used to test and deliver code changes to DataOps pipelines based on the #TrueDataOps principles.
CI/CD is also one of the seven pillars of #TrueDataOps. Let’s turn once again to the truedataops.org website to define CI/CD:
In the software development world, CI/CD is the “practice of frequently integrating new or changed code with the existing central code repository, building and testing it, and having it in a position to deploy on-demand.” These integrations must happen often enough to have no gap between each commit and build, and developers can trap any errors before the code is deployed to production.
CI/CD primarily depends on using a source control system with feature branch functionality to manage source code revisions to achieve these goals.
Note: All logic and jobs performed on data as part of a data pipeline must be treated as code and stored in the source control system (git). Not only does this ensure that source code does not get lost, but it also ensures improved data governance and data security as all data-related operations are logged and tracked.
A practical application of using CI/CD as part of the data ecosystem
Let’s consider the following example of using CI/CD to deploy new code revisions based on existing code stored in a git master branch.
In this scenario, we have received a request from the business to add a new column, the sensor description, to the electrical usage table. While this is a straightforward example, its primary aim is to demonstrate how CI/CD is used to implement changes to an existing DataOps pipeline.
Like the DevOps process, adding a new column to a database table must start with creating a new feature branch from the master branch.
Note: Because data has state and DataOps pipelines ELT data, the data must be included in this new feature branch. Secondly, because this feature branch is independent of the master branch and production data, you can make continuous improvements until this change is ready to go live.
Once the feature branch has been created, the next step is to go ahead and add the new column to the electrical usage table. Because we use SOLE (our Snowflake Object Lifecycle Engine) to manage the system’s DDL (Data Definition Language) statements, we only need to add the column name and type to the existing YAML table configuration script.
The existing configuration is as follows:
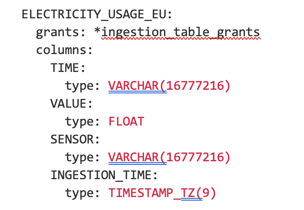
And the YAML configuration with the new column added is as follows:

Because SOLE is a declarative engine, every time a pipeline is run, SOLE looks at these YAML configuration statements and the current state of the database to run any changes needed to return the database to its perfect state described in the YAML configuration scripts.
It is also essential to develop a set of tests, including unit and regression tests, as part of this change and add them to the source code repository. This ensures that the change is rigorously tested before being merged into the master branch and deployed to production.
In summary, the CI/CD function integrates or merges this feature branch with the master branch once you are satisfied with this change and then deploys the changes to production.
Ready to get started?
Sign up for your free 14-day trial of DataOps.Live on Snowflake Partner Connect today!




