
 By
Jevgenijs Jelistratovs + Raj Joseph
By
Jevgenijs Jelistratovs + Raj Joseph

In recent years, Data Mesh has significantly popularized the data product concept. It’s a trend that mature organizations, recognizing data as an asset, have started embracing and implementing.
However, no universal standard for implementing a data product has been established. With different interpretations of “data products” appearing, datasets, data as an asset, or data as a product varies from enterprise to enterprise. For instance, enterprise architecture is geared towards operational architecture and is used to recognize data as a by-product of the processes. But in later versions, TOGAF—a leading enterprise architecture framework—included “Data is an Asset” as one of its architecture principles, which already incorporates several data product principles.
Despite recognition of the importance of data by enterprise architecture, it revolves around the operational rather than analytical function, and we saw the birth of the concept of data products and surrounding architecture frameworks; hence, data mesh.
In data product development to date, we rarely see a data product definition materialize. Of course, regardless of data product implementation, we could describe and represent data products or their components in sophisticated data catalogs such as Alation, Collibra, or data.world. But we are talking of a more complex definition of data products, considering the dataset, which one can often find at data marketplaces and other surrounding aspects.

Unlike the dataset or table, besides the physical schema (physical metadata structure) definition, a data product contains components like Governance, Service Level Objectives (SLO) and Indicators (SLI), data sources (Input Ports) and consumable outputs (Output Ports), business definition, and more. Apart from structural complexity, we can consider a data product successful if it brings value to the organization.
What makes data products different from previous approaches is the way data products are designed and governed. We can sum up the design principles with the ten data product characteristics represented in the picture below. (If you want to learn more details, check out this webinar). In a nutshell, data products should be composable, interchangeable, trustworthy, and valuable in the organization.
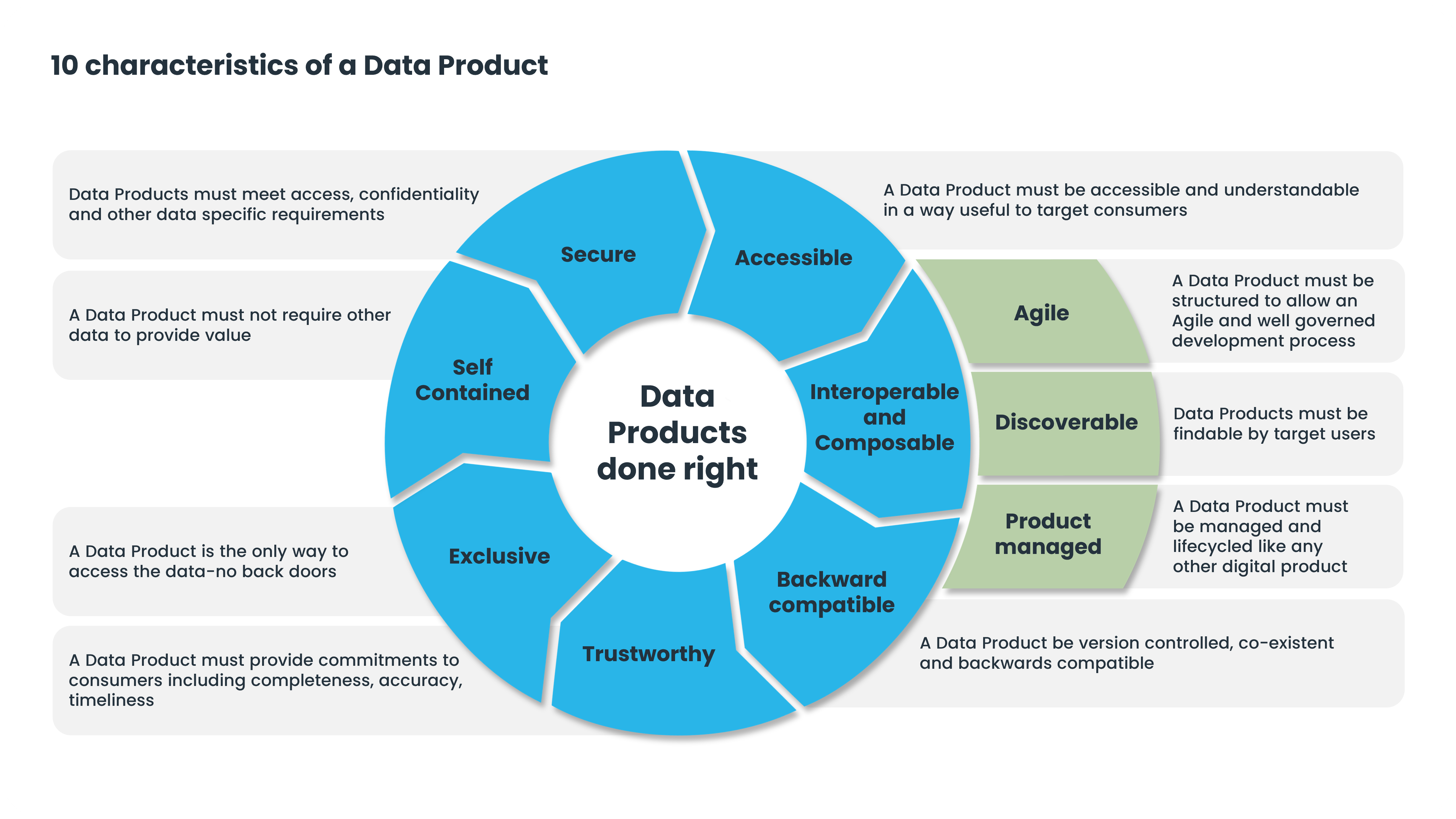
Only a few companies have tried implementing data products and mesh, and even fewer have succeeded. And it is understandable because before DataOps.live, no platform could holistically realize data product potential. Objective complexity lies in implementing data products to benefit from all those characteristics, as until today, there were no solutions that could support data products out of the box.
DataOps.live solved that problem by developing a data product definition and creating a data product engine to manage the data product lifecycle. Data product definition is a materialized manifestation of all the data product components, compiled into a data pipeline to manage the end-to-end data product lifecycle from definition to publishing into the data catalog.
Our customers pioneered one of the first true implementations of data products and data mesh. Check out the Roche case study, where we mentioned the benefits that Roche managed to achieve, like scaling from one release every three months to 120+ releases per month.
When delivering data products, it's crucial to provide trustworthy products. In fact, “trustworthiness” is one of the key characteristics of a data product, represented as SLO and SLI in the data product definition.
Without trustworthy data, the whole framework is at risk. Today, we want to showcase how DQLabs and DataOps.live can significantly simplify the ability to provide quality data products with semantic-based quality.
You don’t want to start ML training on customer churn probability and push this into your Snowflake CSR app on poor-quality data. Not only is it expensive to run Snowpark models, but mistakes could lead to business consequences and loss. Thus, while building your pipeline on top of Snowpark, you first want to include a data quality stage.
However, one of the problems working with data products is that their components contain vast competence areas, from defining data products to governance and ownership pieces to SLO/SLI and technical implementation. The primary user of DataOps.live is typically a data engineer or DataOps developer responsible for transforming and creating the technical metadata part of the data product and ensuring consistency.
At the same time, while it's possible to manage all ten data product characteristics, it requires significant competence from a data engineer. Data engineers usually need an extra communication level with data quality engineers to understand the data quality rules—and human communication is often a slow, inefficient, and error-prone process.
However, with DQ Labs, there is another way of managing data quality: DQ rules based on semantics, aka data classes. DQLabs is an automated, no-code, MODERN DATA QUALITY platform that delivers reliable and accurate data for better business outcomes. DQLabs offer cutting-edge automation across data observability, data quality measures, and remediation powered by semantic discovery to deliver “fit-for-purpose” data for consumption across reporting and analytics.

With AI-based semantic classification and MLOps, DQLabs builds scalable, optimized ML workflows with superior price/performance and near-zero maintenance for anomaly detection, root cause analysis, no-code quality, observability checks, and identifying business terms. DQLabs increases trust in the validity and accuracy of the data by discovering out-of-the-box 250+ observability and quality metrics, automating deep column profiling checks, matching business terms with data assets using data classes, and documenting lineage down to the column level, and providing impact and root cause analysis for immediate resolution.
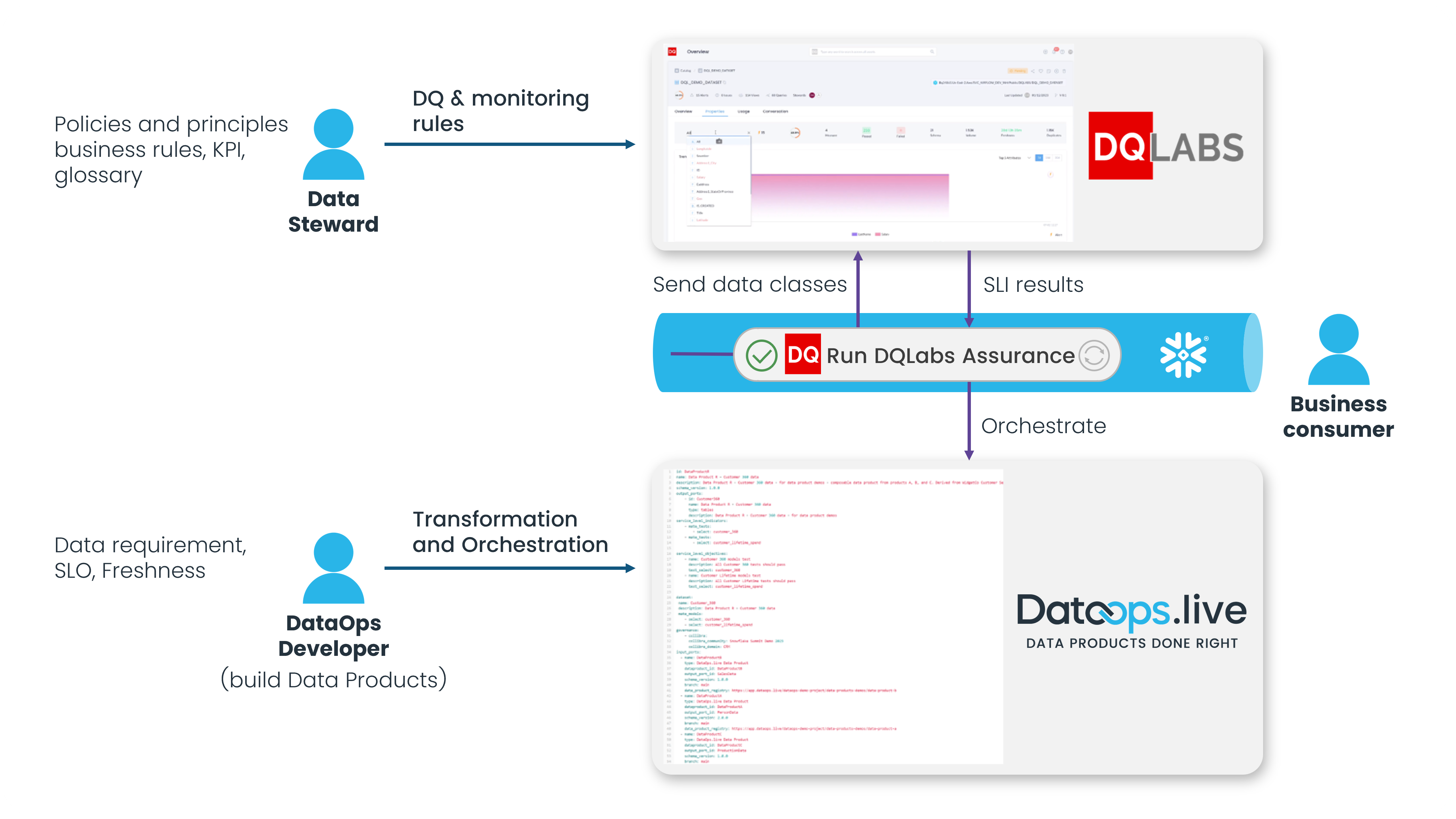
Now, instead of learning data quality rule structure, data governance policies, and principles around data quality, the data engineer can describe something they already know—data classes they’re working on that are essential to this data product. DataOps.live, in turn, sends DQLabs information on which data products need to be added to the monitoring and quality scope and which data classes to monitor.
This way, we simplify the responsibility of the data engineer to let them focus on preparing, transforming, and testing data and leave data quality to the data steward. On the other hand, the data engineer pushes the delivered data products to the data quality layer and, through a loosely coupled semantic layer, makes it possible for the data steward to post-factum monitor and optimize data product quality.
Of course, more advanced data engineers can still describe their own SLO and SLI structure. Still, instead of using an external DQ rule ID, we can use the SLO as data classes/terms grouping into the correct categories that need to be observed. The DataOps.live data product definition allows the definition of SLO and respective SLI (as DQLabs KPIs/Terms), delivered to the data quality and observability layer in DQLabs via pipeline orchestration.
In the data products engine, it’s possible to make decisions based on achieving the SLO. For example, suppose your source data product is not reaching the quality thresholds in the latest refresh. In that case, we may want to skip the refresh and run on the previous data version while the data quality team resolves data quality issues.
Adoption of all practices also heavily depends on simplicity of use. We want to improve such an essential activity as data quality. Quality and testing are critical activities in the pipeline. The DQLabs and DataOps.live collaboration makes it simple for data engineers and stewards to ensure data product quality.
Here is more information on DQLabs Modern Data Quality Platform and its automation of out-of-the-box semantic discovery and observability/quality metrics.

.png?width=400&height=250&name=image%20(1).png)

