
 By
DataOps.live
By
DataOps.live

There are two major approaches to programming: imperative and declarative. Imperative programming tells a system how to do something step by step. Declarative programming defines what the desired outcome should be and lets the system figure out how to get there—an important distinction for modern data engineers managing complex, stateful data systems. But data engineers may not be as familiar with these terms as software engineers are.
Programmers learn about imperative vs declarative approaches early on. Data engineers don’t always have the programming background that software engineers do. As a result, many data engineers are unfamiliar with the difference between imperative and declarative methods. “I was doing declarative, I just didn’t know it was called declarative,” says #TrueDataOps host Kent Graziano.
We’ve put together everything data engineers should know about imperative and declarative approaches in software and data. Read on for definitions of imperative and declarative, examples of declarative compilers, and explanations of imperative vs declarative database schema management.
Finally, learn whether DataOps.live takes an imperative or declarative approach to data, and why.
In this guide:
-
The Difference Between Imperative and Declarative Programming
-
What Data Engineers Should Know about Declarative and Imperative
Declarative and imperative programming are two different ways of instructing computers to perform tasks. Imperative programming focuses on how a task should be completed, using explicit step-by-step commands. Declarative programming focuses on what the desired result should be, allowing the system to determine the steps needed to reach that outcome.
Before we go deeper, a quick grammar lesson. The terms “imperative” and “declarative” come from linguistics. Don’t worry, we’ll keep it short and it really is helpful.
Grammatically speaking, a “declarative” mood is used for statements of fact or opinion. When you tell your dog “You’re a good girl,” or when Michael Scott says “I declare bankruptcy,” these are declarative statements.
The “imperative” mood is used for commands. This is when you tell your dog “Sit…stay…go get it!” or when Dwight Schrute says, “You are coming and that’s an order.”
Imperative programming is the traditional approach to programming. The basic concept behind it is pretty simple. That grammar lesson should give you a clue: the imperative method is based on commands.
TechTarget defines imperative programming this way: “In imperative programming, every operation is coded and the code itself specifies how the problem is to be solved, which means that pre-coded models are not called on.”
In short, in imperative programming, your system knows nothing. Your code tells the system what to do at every step to achieve the end result you want.
Making a Peanut Butter and Jelly Sandwich with Imperative Programming
Introductory coding instructors love to teach the concept of imperative programming with a classic activity: the Making a Peanut Butter and Jelly Sandwich (or PB&J) exercise.
In this exercise, students are told to write detailed instructions for making a peanut butter and jelly sandwich.
A student’s first try at instructions might look like this:
- Get two slices of bread
- Put peanut butter on one slice
- Put jelly on the other slice
- Put them together
Then, someone attempts to make a peanut butter and jelly sandwich using those instructions—and only those instructions. The sandwich maker has been prompted to imagine they’re an alien, or a robot, with no context for sandwich making besides the written instructions they receive.
The process tends to fail early and often. Why?
Take another look at the instructions above. To begin, there are no instructions for how to open a bag of bread. “Put peanut butter on one slice” is a very vague instruction—with your fingers? Spread along the crust, or in a glob on one side? And hang on, the peanut butter jar isn’t even open!
This exercise helps learners think about how to break a problem down into the smallest subtasks to give the clearest possible instructions. It's a great way to get into an imperative frame of mind. It’s also so straightforward and nontechnical that anyone can do it. In fact, PB&J challenges are becoming popular to teach programming concepts to kids.
How do we define declarative programming? “Declarative programming is a method to abstract away the control flow for logic required for software to perform an action and instead involves stating what the task or desired outcome is,” according to TechTarget.
That definition sums it up nicely, though we don’t necessarily agree with everything else in TechTarget’s article defining declarative programming. We’ll explain that difference of opinion later on. For now, let’s look at how a declarative approach changes our peanut butter and jelly sandwich activity.
We’ve established that the imperative method involves coding step-by-step instructions to achieve a specific outcome. On the other hand, a declarative approach involves defining the desired result and letting the system interpret what’s needed based on preprogrammed rules, models, and logic.
The key difference between imperative and declarative is that in imperative you’re dictating instructions, and in declarative the system knows enough to figure out instructions on its own. In an imperative approach, you’re working with a blank slate. In the declarative approach, the system already has context and can work out what you want based on the entry of your desired target or end state.
To extend the peanut butter and jelly sandwich exercise, a declarative approach would be having someone in the kitchen who's already a competent sandwich maker. You could just show them a picture of a peanut butter and jelly sandwich, and they’d make you one.
What if you wanted a different outcome? In a declarative model, you could just show your sandwich maker a picture of a peanut butter, jelly, and banana sandwich and they’d make it for you. In an imperative model, you’d need to rewrite your instructions, adding steps in the middle for peeling a banana, cutting up the fruit inside, and placing a layer of banana pieces onto the slice of bread that’s spread with peanut butter.
What is the Relationship between Declarative and Imperative?
While TechTarget’s definition (and almost every other source) goes on to describe declarative programming as “the opposite of imperative programming,” we disagree. A declarative approach is an abstraction based on our interaction with the system. When you look under the hood, all systems depend on a set of instructions.
That’s right, even declarative programming relies on imperative instructions. Instead of the system depending on you to supply those instructions, they are predefined. When you enter a desired end state, the system analyzes the current state, target state, and preprogrammed information, and uses a compiler to work back a set of imperative instructions from your stated goal. The system will then execute on those instructions.
What is a compiler? Doug Woos, Computer Science lecturer at Brown University, gives this helpful definition of a compiler: “A compiler is a program that takes in source code written in one language (called the source language) and returns source code written in another language (called the target language).”
Since that all happens behind the scenes and all we have to do is declare what we want, we call it declarative.
The declarative approach relies on predefined models, in other words, prior knowledge. The exact address, “221b Baker Street, Marylebone, London, England” serves as a great definition of the end state, but it’s unhelpful if you’re not already familiar with the area. To know how to get there, you’ll need a declarative compiler.
So, what is a declarative compiler? A declarative compiler is a program that will receive a statement of a desired end state, compare it to the current state, and return imperative instructions to achieve that end state.
In this case, you have an address, and you need directions to that address. Assuming there’s no London cabbie available to help, Google Maps can serve as a declarative compiler:

Google Maps as an example of a declarative compiler
And indeed, Google Maps provides a set of clear, step-by-step instructions. You entered a declarative goal into the declarative compiler, and it returned a set of imperative steps.
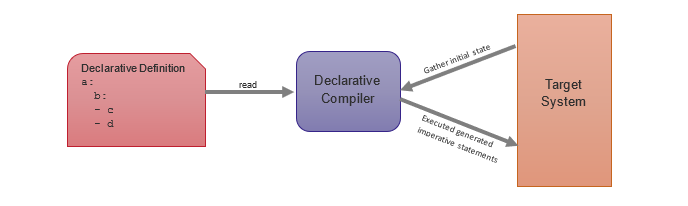
Diagram of a declarative compiler
Real-world Examples of Declarative vs Imperative
Enough about sandwiches. Let’s take a look at a more realistic example: navigation systems. Let’s say you’re trying to get to Sherlock Holmes’ flat.
A declarative example would be to simply provide an address:
- 221b Baker Street, Marylebone, London, England
In an imperative example, you don’t define the target state. You provide steps to get there:
- Face north, walk 1.2 miles, turn right onto Oxford Street, walk 200 yards, turn left, walk 245 feet, and turn to the door on the right
Since it is a set of instructions, the imperative list is full of verbs or actions—“turn” and “walk.”
Note that an imperative approach relies on a specific known start point or current state. The imperative example above really only works if you’re starting in one predetermined location in London. What if you tried to follow those instructions starting in Brisbane, Australia? You could probably “face north” and “walk 1.2 miles," but you wouldn’t be able to “turn right onto Oxford Street.”
At that point, the process has failed, and you’re lost—in an unknown/undefined state. Even if you started just a block west of the expected start point in London, the imperative directions would fail.
You might as well try to make a peanut butter and jelly sandwich without knowing how to open a bag of bread.
What Data Engineers Should Know about Declarative and Imperative
Now, we’re ready to look at declarative and imperative data approaches. You may not have known it before, but you’re using declarative compilers in database management.
The most typical example of changing the state of a database is to create a table. Here’s an imperative way to do that:

How can we tell that this is an imperative approach? The big clue is that the first word is a verb: “CREATE.”
What would a declarative approach to the same goal look like using YML?

The database, however, doesn’t speak YML. Like most systems, it can only follow imperative instructions. You can’t just use this code directly. You can, however, pass our declarative definitions into a compiler. That declarative compiler will compare the current state to the desired state and produce an imperative output.
Example Of Imperative vs Declarative Database Changes
You may be thinking, “This declarative approach sounds like a lot more work, why would anyone bother with it?”
It all comes down to state.
Consider a case where you need to create a People table. There is no People table yet.
Imperative approach: Execute:

Creates a People table with 5 columns.
Declarative approach: The declarative compiler takes your declarative definition, and looks at the current state (“no People table”). It determines that since there is no table, the best way to turn the current state into the desired state is to execute:
The end result in either case is the same. However, consider if there is already a People table with 3 columns:
Imperative approach:
Execute:
Since a People table already exists, this code would return an error.

Declarative approach:
The declarative compiler takes the declarative definition and reviews the current state:
“People table already exists with 3 columns (PersonID, LastName, FirstName)”).
It determines that since there is already a table with 3 columns, the best way to turn the current state into the desired state is to execute:
This works!
The Power Of The Declarative Approach to Data
A declarative approach to data is powerful because it’s adaptive. It reviews the initial state, and can dynamically create the correct imperative instructions. Going back to the Sherlock Holmes example, you can get directions from Google Maps that will work from anywhere, just by entering the address.
That’s because Google Maps compiles imperative instructions based on your current location. If you change the start location and ask for directions, it will take that into account and generate a different set of instructions.
In contrast, imperative instructions are usually based on an assumed initial state and become invalid and inexecutable in any other initial state.
The Spectrum of Approaches from Imperative to Declarative
Once again, we see that imperative and declarative approaches aren’t actually in opposition. They are more like points on a spectrum. In between, you can find hybrid methods, including log-based and check-based approaches. Let’s take a closer look at each of these points on the spectrum.
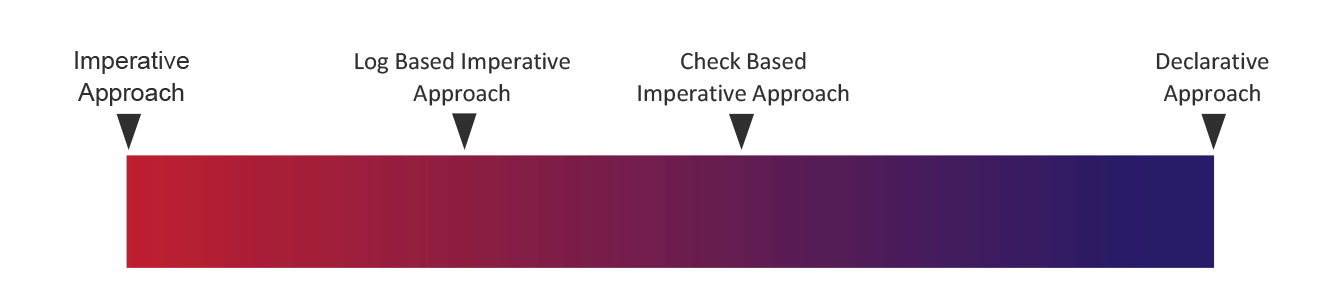
Drawbacks of Pure Imperative Database Schema Management
When using a purely imperative approach, you have to detail every step in every process. For example, “CREATE OR REPLACE TABLE.” This approach is more prone to data loss since there is no version control, and if data already exists, you have to remember to code the steps to save the data first.
For example, you could use SQL, an imperative language, to execute a series of operations. It would look something like this:
CREATE DATABASE ...
USE DATABASE ...
CREATE SCHEMA ...
USE SCHEMA ...
CREATE TABLE ...
CREATE ROLE ...
GRANT ROLE ... TO TABLE ...
The above code expects the starting state in which there is no existing database, schema, or table. But if the database already did exist when the code was run, it would return an error.
But be glad it’s DROP TABLE, CREATE TABLE and not CREATE OR REPLACE TABLE, which will wipe out the old table and all its data. That would lead to reports breaking, probably right as an executive wanted to look at them. You’d have to reload all the load scripts, costing time and money.
Drawbacks of imperative processes include:
- Need to know and define starting point - changes may fail if the starting point is not perfectly defined, for example if an object to be altered does not yet exist
- Need to execute changes in sequence - leading to complex serial or parallel branching processes (DAGs)
- Risk that failure will leave database in unknown state
- Need for familiarity with low-level database commands and operations - including limiting factors such as execution times and potential race conditions
Pros and Cons of Log-Based Database Schema Management
In a log-based approach, the admin creates each new imperative statement in a separate step. Each step is given a unique identifier. A log, which may reside in an external state store or in the target database itself, tracks which steps have been applied to which database.
The engine reads a list of all the possible steps, reviews which steps have been already applied, and then applies the missing ones.
Going back to our People table example, you could start with this:
0001.sql

This would create the table. Later, when new columns need to be added, you could create a following:
0002.sql
0003.sql
The next time the engine runs it will detect that the highest ID that has been applied is 0001, and it will apply 0002 and 0003.
The log-based approach is popular in the wider database community. It is well-tested. The log-based approach can support multiple different instances of a database, for example Dev, QA, Prod, by keeping separate logs for each.
However, it depends on two fundamental assumptions:
- No changes can be made by a person or another system
- The database experiences a single, linear set of changes that always move forward
In reality, neither of these assumptions is safe to make in a modern cloud environment.
When multiple people are working on a database concurrently, the log-based approach also runs into a scaling problem. If the latest file is ‘0003’, several people working on new features or changes at once could all expect to name their step ‘0004’. By the time an engineer realizes there’s a conflict and decides to move up to ‘0005,’ that will have been taken, too.
Pros and Cons of Check-Based Database Schema Management
A check-based approach runs a fundamentally imperative statement, but only if a particular check has been met.
In a pure imperative approach, you could execute:
The first time you execute this, it will work. Every subsequent time, it will throw an error, such as:

However, if you write:
Again, the first time you run this, it will drop the table. Every subsequent time, it will return a graceful message such as:
The inbuilt capabilities of the database provide not just a way to define an action: “DROP TABLE People”; but also a state that needs to exist to try to actually execute this action: “IF EXISTS”.
The database will run the check first, which is a bit like a declarative approach, reviewing the initial state. Then, based on the results of that check, the system will decide whether to run the action or not.
That seems like an improvement. Does this solve all our problems? Unfortunately, no, because this functionality is only available for specific use cases in any database.
You could execute:
A check-based system will check if the table exists. If the table doesn’t exist, it will create it. But if the table does exist, it will return a graceful message and exit — even if the table that exists is different from the one defined.

Unfortunately, you can’t generally run a statement like the following:
This is simply not a supported statement in most databases, with PostgresSQL and MariaDB as notable exceptions.
But no database today has enough “IF NOT EXISTS” functionality to support all use cases. Also, in some situations “IF NOT EXISTS” is not enough—for example, a DDL to alter the data type of an existing column. In most databases you can alter a NUMBER column to a VARCHAR but not the reverse. And altering a VARCHAR(60) to a VARCHAR(20) will work, but it will truncate any existing data strings over 20 characters long (probably not what you want).
Advantages of Declarative Database Schema Management
When you compare an imperative vs declarative approach to data engineering, declarative schema management wins hands-down.
Benefits of declarative database schema management include:
- Better version control, which ensures traceability from development to QA to production
- More dynamic, adapting to state changes instead of depending on fixed variables
- No data duplication to make changes. Thanks to version control in declarative database schema, there’s no need to save a separate backup before making the change
- Faster and simpler setup with declarative database schema, instead of starting from scratch to code every new database, all you have to do is run a create table statement and a few alter statements
Snowflake Zero Copy Clone allows you to take full advantage of a declarative approach to data so you don’t have to rebuild the existing schema from scratch every time you want to create a new branch or version. Snowflake effectively creates an identical duplicate of your cloud database, table, or schema by generating new metadata entries that point to micro-partitions of the source object. Since no data is actually copied, it doesn’t take up any additional storage space.
DataOps and the Declarative Approach to Data
DataOps prizes efficiency and reliability, so it should be no surprise to learn that declarative database schema management is our preference.
We believe that fully declarative database schema management is the long-term key to success.
Here’s why: when you look at the history of progress in infrastructure, networking, and other areas of technology, a pattern emerges. That pattern is an inexorable march from imperative to declarative.
The Evolution of Declarative Database Management Schema
Of course, early on data engineers had no choice but to code databases using an imperative approach. But as enterprises grew to millions of rows of data and thousands of worldwide users, imperative approaches became unwieldy. Some adopted a log-based or check-based approach. Those methods were steps toward declarative database management, but they didn’t shake all the drawbacks of the imperative approach.
Admins would save backups of databases, and old versions full of old data took up disk space in on-premises data storage. Also, as the world became more interconnected and data moved to the cloud, two other challenges emerged:
-
Round-the-clock global activity meant users were always online. You couldn’t wait for data to be offline overnight to make changes.
-
With bigger and more global data teams working in cloud data, it became more likely that someone else would be pushing data changes at the same time you were. In an imperative model, editing conflicts cause chaos.
The declarative method solves these problems. With a declarative approach to data in the cloud, a data engineer could flow changes into a live system without disruption using CI/CD principles. In fact, multiple data engineers can introduce changes at once without worrying about breakage, downtime, or data loss. With each encounter, the system adapts to state changes, just like Google Maps adjusts directions based on your current location.
The Future of Declarative Database Schema Management
As we’ve seen across other technologies, a fully declarative approach to data will take some time to mature. While database technologies are not quite there today, we're actively working on projects to make the declarative future a reality for data engineering.
We believe that all use cases today are possible using these simple guidelines:
- Use “CREATE OR REPLACE X” where possible for example when the target object is stateless, or the state doesn’t matter
- Use “CREATE X IF NOT EXISTS” where possible
- Use the conditional execute approach and possibly some convenience wrappers to make specific high-frequency use cases even easier
DataOps.live enables CI/CD for data through version control, monitoring, and deployment automation. You can ensure every change you make is approved, balancing agility and governance. DataOps for Snowflake provides a single pane of glass to manage, observe, and evolve the Snowflake Data Cloud.
/banner-pink.svg)
Request a demo
Speak with a DataOps.live expert today.



