
 By
Guy Adams - CTO, DataOps.live
By
Guy Adams - CTO, DataOps.live

Introduction
DataOps pipelines, based on the #TrueDataOps philosophy, follow the software CI/CD paradigm. Part of this, particularly the Continuous Deployment part of this, usually includes a significant element of the target environment. For example, for a simple Web Application on Kubernetes, not only would a development pipeline build and test the WebApp, but it would create the Pods and Services (and any other related setup) in the Kubernetes cluster as part of deploying the application, and similarly remove all of these when the development of this feature is complete. Phrased another way, the job of a pipeline could be stated as “build and deploy everything required to have the correct version of my application running”—including all of the infrastructure as required.
Why?
If we think about the old way of software development, it looked something like this:

The fixed number of ‘hard’ environments here makes the infrastructure management problem relatively simple but places a huge number of limitations on development engineers, including:
- Huge coordination requirements and time sharing
- More time setting up/resetting environments than actually developing
- Constant conflicts between engineers
- Huge inefficiencies
- Greatly increased time to value
The software world has moved to a far more elastic model:

This uses the dynamic and elastic capabilities of something like Kubernetes to allow developers to create environments as they need them, just for them, for as long as they need them and then to tear them down again afterwards. This has dramatically improved the efficiency of software engineers.
The on-prem/legacy models for data were very similar to those of software:

With all the same challenges and in many cases, actually worse than the software world —to work out whether your Dev server has all the correct versions of some libraries is a pain, but to work out with it has every record of correct data is almost impossible. In particular, there has been a high barrier to creating a database. In the legacy world a database is a meaningful, tangible thing with clear costs associated with it, especially if that database has a considerable volume of data. This in turn creates a high barrier to each developer or even each feature having their own develop environment.
Cloud Data Platforms, specifically Snowflake, now enable data to follow similar models to software, with Snowflake providing the dynamic and elastic capabilities for data that Kubernetes does for software: 
Databases are no longer precious objects with high barriers to creation. In fact they are nothing more than logical containers. In Snowflake a table (and other similar object types) carry actual data, state and information—databases and schemas are little more than logical containers to make them easier to manage at scale. There is therefore a very low barrier to entry to create new databases for individual engineers or individual features to develop and test against, and even with large volumes of data, the use of Zero Copy Clone creates a very low cost to this high value capability.
DataOps Patterns
If the job of a software CI/CD pipeline is “build and deploy everything required to have the correct version of my application running”—including all of the infrastructure as required then it’s reasonable that, as a default design pattern, DataOps.live does the same for data. The pipeline builds all of the infrastructure (primarily using DataOps.live’s Snowflake Object Lifecycle Engine (SOLE) and then builds and deploys the Data Product(s) on top of this:
-1.png?width=973&name=MicrosoftTeams-image%20(2)-1.png)
For many customers, this model works fine. However, for some organizations this is not suitable, for example if there is a corporate requirement around separation of responsibilities for infrastructure.
Separation for Highly Governed Infrastructure
While DataOps allows a large amount of configuration and code to co-exist in a single project, it also supports breaking these out into separate projects. By far the most common separation is to break out a Data Product and its infrastructure.
Infrastructure Project
The Infrastructure Project:
- Contains only the configuration and code to build the infrastructure
- Manages a subset of object types. These can vary based on detailed requirements, but typically would be Account Level objects e.g.

- Has members of the infrastructure team as Owners and Maintainers, i.e. the only ones who can approve changes going into protected branches such as QA and Master
- Has a much simpler pipeline e.g.
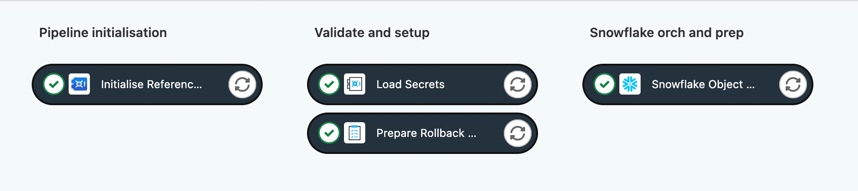
- Typically runs at a lower frequency—maybe daily, or even weekly in a defined maintenance window
However, it doesn’t mean that only members of the infrastructure team can make changes—any permitted member from a Data Product team can create a branch in an infrastructure project, make the changes then need and submit as a request—it just needs a member of the infrastructure team to approve. This means the request is made as an actual proposed new configuration, not a vague text description, cutting down time and mistakes.
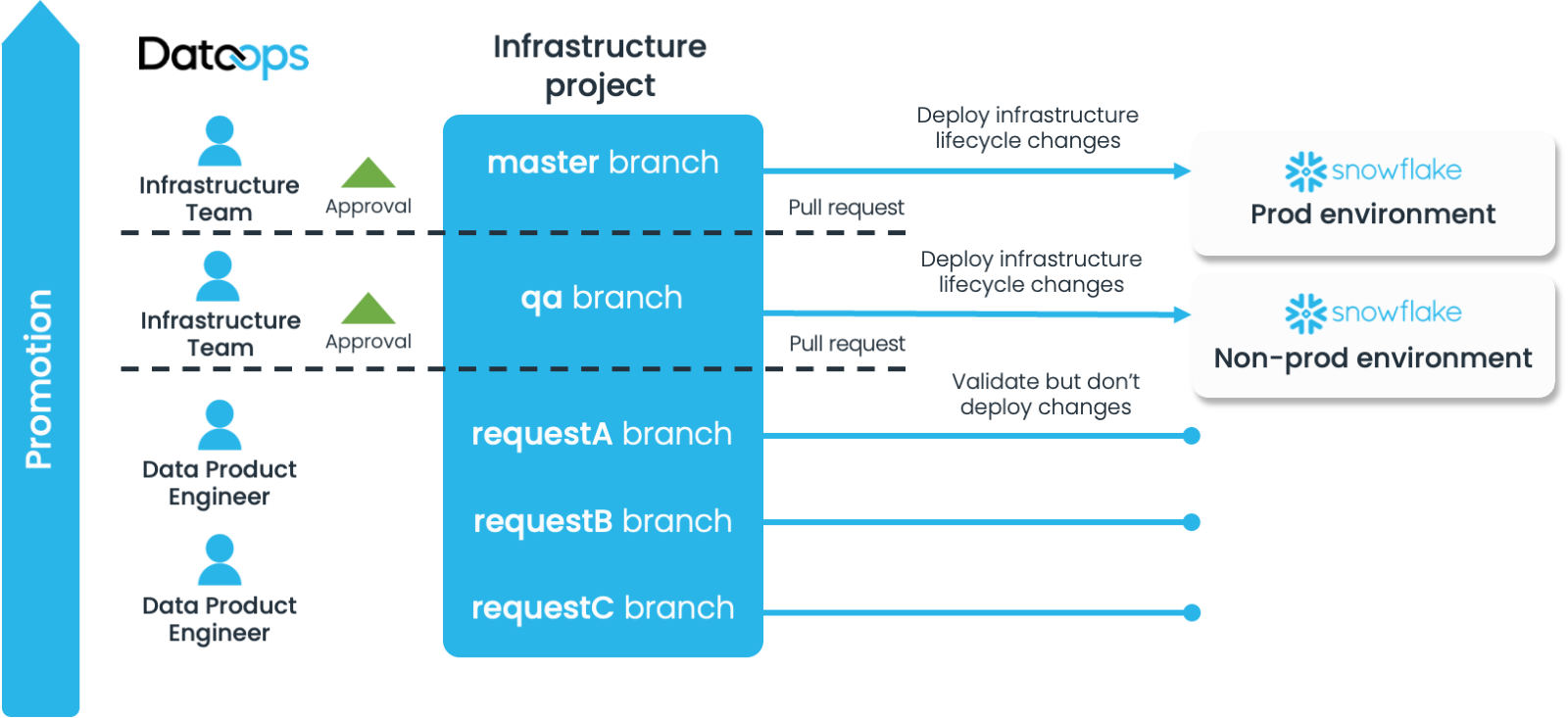
This also means that infrastructure changes, even going through another team for approval can often be achieved in hours rather than days or weeks.
Data Project
In contrast, the Data Project:
- Contains only the configuration and code to ingest, transform, test, observe the data, without worrying about the underlying infrastructure
- Manages a subset of object types. These can vary based on detailed requirements, but typically would be database level objects e.g.
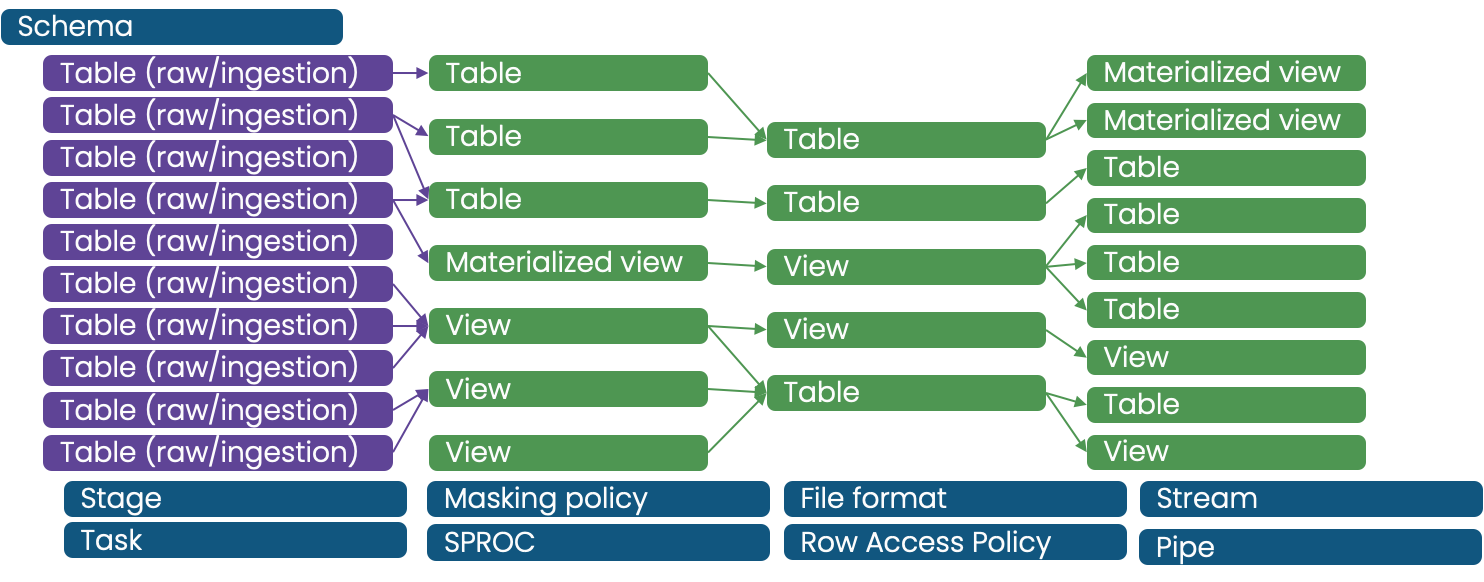
- Has members of the Data Product team as Owners and Maintainers
- Has a more sophisticated pipeline(s)
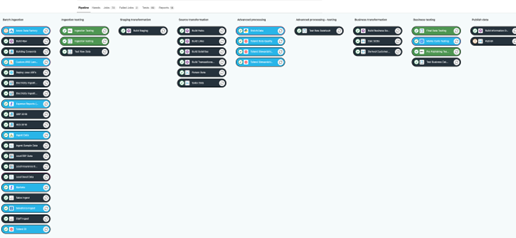
- Typically runs at a higher frequencies, and often different subsets will run at different frequencies based on the availability of data for ingestion
- This all allows the Data Product Engineers to develop rapidly and without need for external approval, within the Infrastructure that has been requested and provided by the Infrastructure Team.
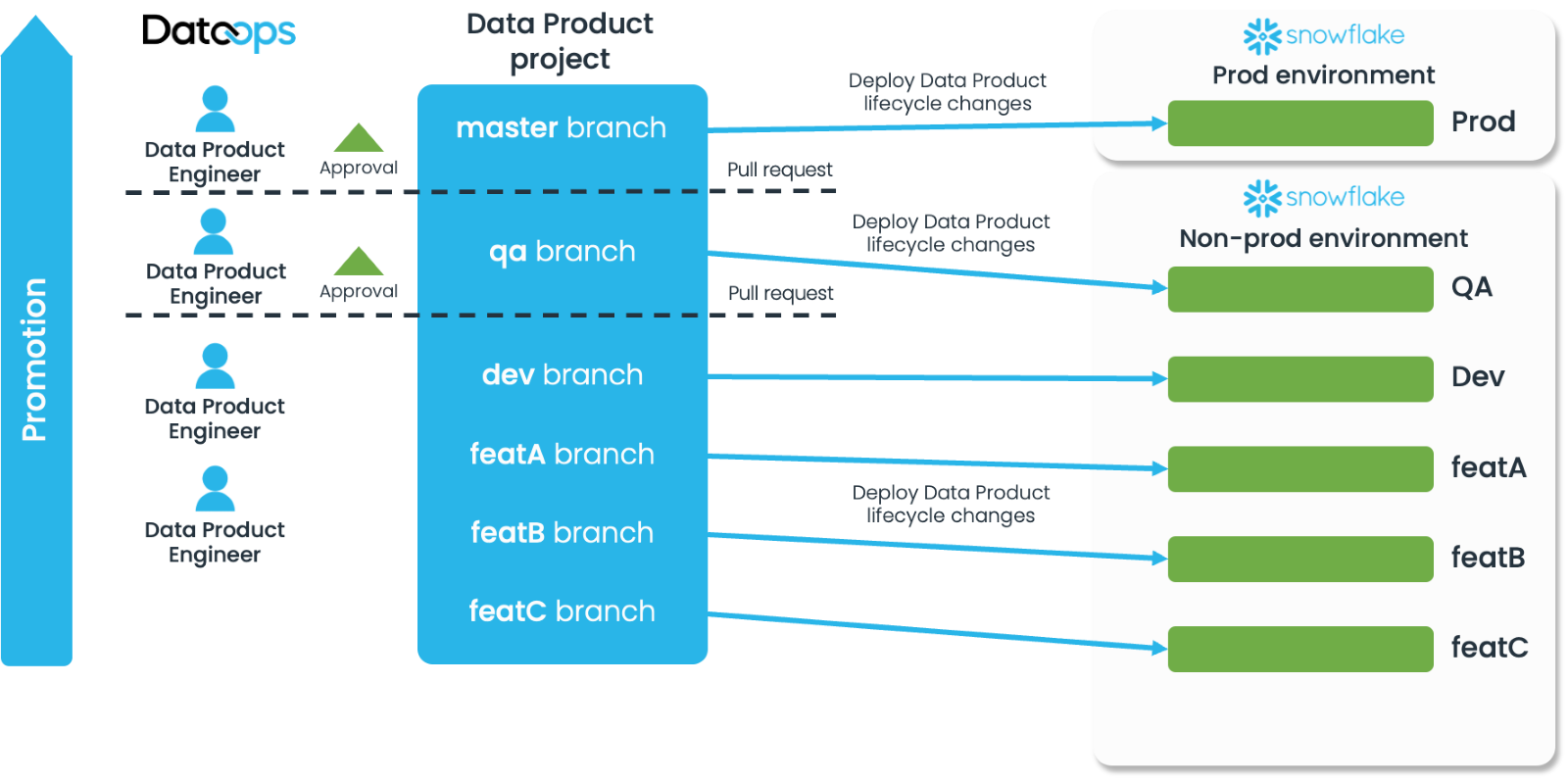
Infrastructure to Data Project Relationship
There are many possible approaches to how many infrastructure projects you have, which will be dictated in the main by the chosen Snowflake architecture and the complexity of the shared versus Data Product specific infrastructure. The simplest model is a single infrastructure project that supports all the Data Product projects:

However, if there is a considerable about of infrastructure specific to each Data Product, these could be split into a core infrastructure project and one per data product, e.g.
Conclusion
Careful attention and a dash of discipline can go a long way towards the success of Data Product teams. Taking its cues from the world of software development, DataOps.live provides an effective approach for developers in a data context to “build and deploy everything required” for their data products to work correctly—supported by Snowflake capabilities, extending to the infrastructure required, and including highly governed environments.
You have the flexibility to separate a Data Product and its infrastructure on a project-by-project basis, while also benefitting from the specific change control, approvals, owners and maintainers that may entail in a way that never risks slowing development and deployment.
Indeed, DataOps is a great way to deliver existing and new data services and products rapidly, despite changing infrastructures.



