
 By
DataOps.live
By
DataOps.live

With the exponentially increasing importance of and value attributed to data, it’s never been more critical to test, observe, and monitor the quality of data being used to develop many different data products, driving strategic decision-making at an organizational level. To enhance and facilitate the development of the highest-quality data products, we have recently announced our support for Soda SQL and Soda Cloud. Succinctly stated, Soda SQL has been fully integrated into our DataOps platform, with full support for Soda Cloud.
Soda SQL and Soda Cloud are developed by Soda, the company co-founded by Maarten Masschelein and Tom Baeyens. Their mission is to bring everyone closer to data by creating Soda Cloud, a data monitoring platform designed to provide end-to-end observability into and control of your data, including monitoring, alerting, and testing to ensure data fitness throughout your data’s lifecycle.
What is Soda SQL?
On 9 February 2021, Soda released Soda SQL, an open-source data testing, monitoring, and profiling tool for data-intensive environments. The first tool in a suite of open-source developer tools designed to be integrated with your existing data pipelines or workflows.
The Soda SQL documentation describes Soda SQL as an “open-source command-line tool. It utilizes user-defined input to prepare SQL queries that run tests on tables in a database to find invalid, missing, or unexpected data.”
Soda SQL protects against silent data issues and protects your downstream data consumers, allowing you to:
- Test your data at multiple points along any data pipelines
- Extract metrics and column profiles through super-efficient SQL
- Complete control over metrics and queries through declarative config files
Therefore, implementing Soda SQL will help reduce data downtime, spend less time firefighting, and gain a better reputation through the consistent delivery of high-quality data to downstream consumers.
However, installing and setting up Soda SQL using the command line, ensuring that all the dependencies are correctly linked, setting it up in a scalable and highly available topology, and linking your Soda SQL installation to your Soda Cloud account can be challenging. Part of this installation and setup includes:
- Creating a warehouse YAML file and an environment variables YAML file
- Working out how to securely store your credentials
- Informing Soda which warehouse tables to scan
- Tracking and testing future version changes
- Creating a highly available way of scheduling and running Soda SQL
In the future, Soda will be adding forecasting to its list of metrics offered through SQL Cloud. For instance, if you have a test that checks whether the total number of table rows is less than 100 million rows. Once this test has run and determined that there are 95 million rows, the forecasting functionality will alert the data team, stating that the table's total row count will soon exceed the maximum (100 million).
Lastly, the results of the Soda scans are either viewed in Soda SQL’s CLI (Command Line Interface) or Soda Cloud’s Web User Interface.
Note: To view the output from the Soda SQL scans in Soda Cloud, you must have a Soda Cloud account, and Soda SQL must be connected. When each scan has been completed, Soda SQL will automatically push its results to Soda Cloud.
Soda SQL and DataOPs.live
Soda SQL can either be used on its own to scan your data or integrated into your existing data pipeline. Because of the potential value Soda SQL has to offer our customers, we have integrated Soda SQL into our DataOps platform. We have created a runner or integration point between our DataOps platform and Soda SQL, providing our clients with the functionality to orchestrate Soda SQL from within a DataOps pipeline.
Soda SQL’s primary aim is automated testing. Although our DataOps pipelines already have automated testing built-in as part of our Modeling and Transformation engine, there is no one right tool that meets every use case. By adding Soda SQL functionality to our DataOps pipelines, we have added additional testing depth and richness to the DataOps platform.
By way of expanding on this topic, let’s look at how we have integrated Soda SQL into our DataOps pipelines.
Jobs
We run jobs in our DataOps pipelines. Therefore, it is essential to create one (or more) jobs to run the Soda SQL tests. A typical Soda SQL job in DataOps would look like this:
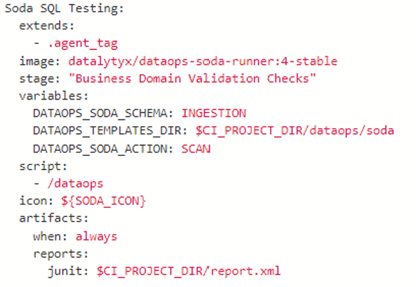
The DataOps web interface includes a directory structure for all the tables you want to monitor. You must create a single YAML file for each table containing details of all the tests you want to run and what metrics you want to track. For example:
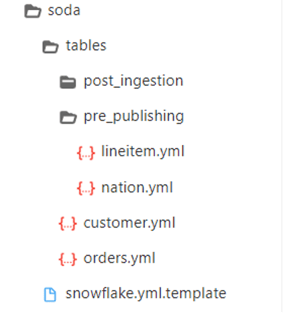
For additional information on creating table scan YAML files, refer to the Soda SQL documentation.
Tags and Tagging
The DataOps Modelling and Transformation Test Engine supports tags, so we have added the functionality to group sets of tests together by tagging them with the same tag. Therefore, we can run different groups of tests at different parts of the DataOps pipeline. Because Soda SQL does not support tagging, we’ve created sub-directories under the soda directory for each set of tests. Thus, when creating jobs, you can implement the principle of tagging by using directories and sub-directories e.g.
You must also create a unique job for each of the groups of tagged tests and run the jobs in the order that the test sets must be run. The image below shows two Soda jobs, SUB_DIR Testing and Soda SQL testing. Each of these jobs contains the instructions to run a tagged group of tests. The order of these jobs shows that the SUB_DIR Testing job is run before the Soda SQL testing job.
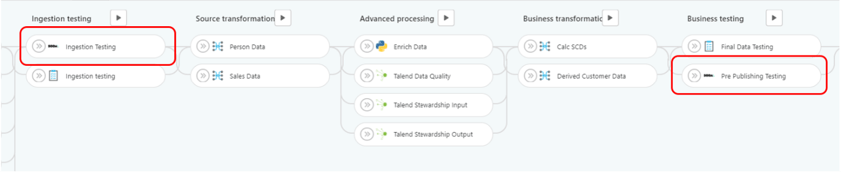
Note: As highlighted above, should one of these Soda SQL testing jobs fail, the DataOps pipeline will stop running. As a result, bad data will not be allowed to run through this pipeline.
Output
Soda SQL’s default output is the CLI.
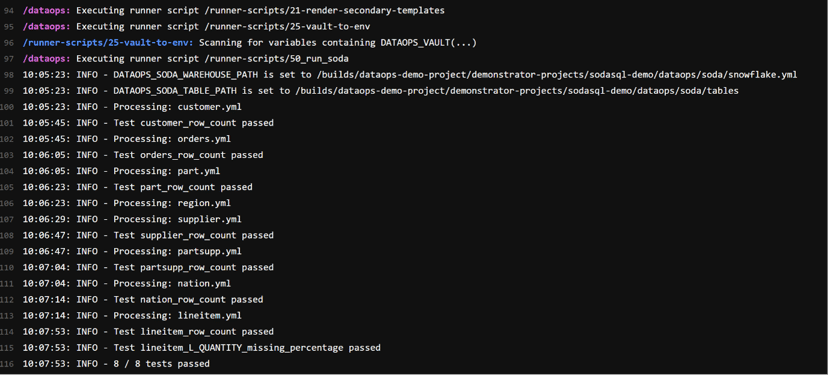
We have integrated the table scan outputs into our DataOps pipeline test results:
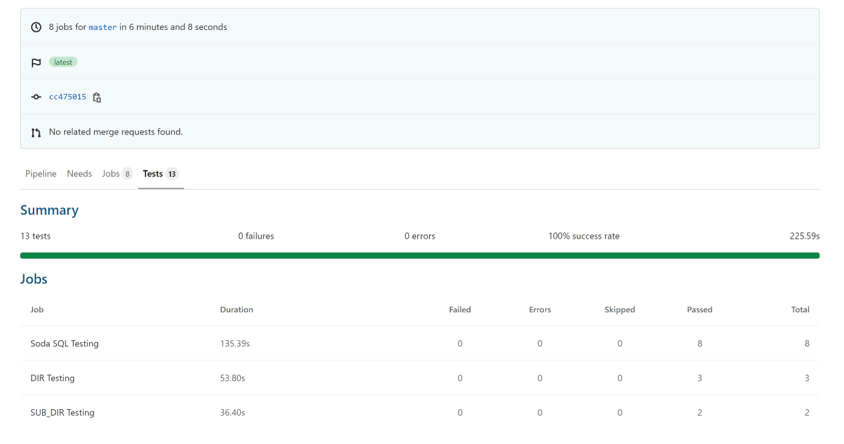
So, you can see the tests, whether they have passed or failed, and drill down into some of the result details:
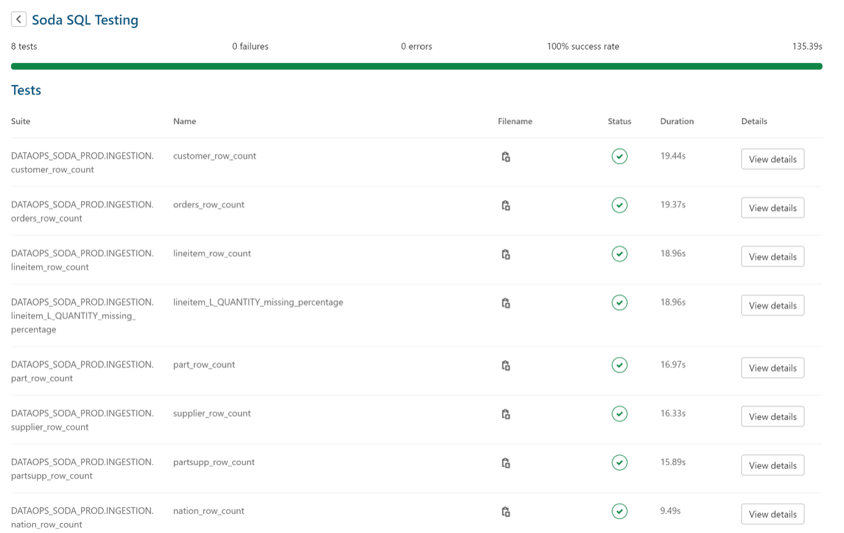
This means you can easily view the test results in the DataOps platform without resorting to text output. However, we don’t want to reinvent the wheel regarding the more advanced monitoring, alerting, and data profiling functions Soda Cloud has. Soda is doing a great job adding value to the Soda SQL results into Soda Cloud. Thus, you should consider signing up for a Soda Cloud account.
The Merits of using Soda SQL from within DataOPs.live
The benefits of using Soda SQL from within, or the key pieces of value added to, the DataOps platform includes:
Ease of use and reliable operation
It is easier to use Soda SQL as part of our DataOps pipelines rather than a standalone tool.
We manage the initial installation, setups, dependency management, and integration with the rest of your data ecosystem. And we also ensure that you are always using an up-to-date, tested version. Therefore, you don’t need to worry about any of these tasks.
Since Soda SQL is kicked off by the DataOps runner, which can already be run in several highly available ways, the Soda SQL execution inherits this high availability. You can also use our runner to generate the first versions of all the table YAML files.
Improved Security
The default Soda SQL installation stores its environment variables in a hidden folder (~/.soda/) in the user’s home directory. In other words, this folder will not be displayed in the desktop environment’s file explorer. Unfortunately, this approach does not meet the security requirements of most enterprise organizations.
The DataOps platform employs a robust secrets management policy, storing all its user details or secrets in a secure vault on the DataOps Runner or in an Enterprise Secrets Manager, such as AWS Secrets Manager and Azure KeyVault. Most of the details you need are already in the DataOps platform. Therefore, you only need to add three new keys to the DataOps security vault to use the Soda SQL runner.
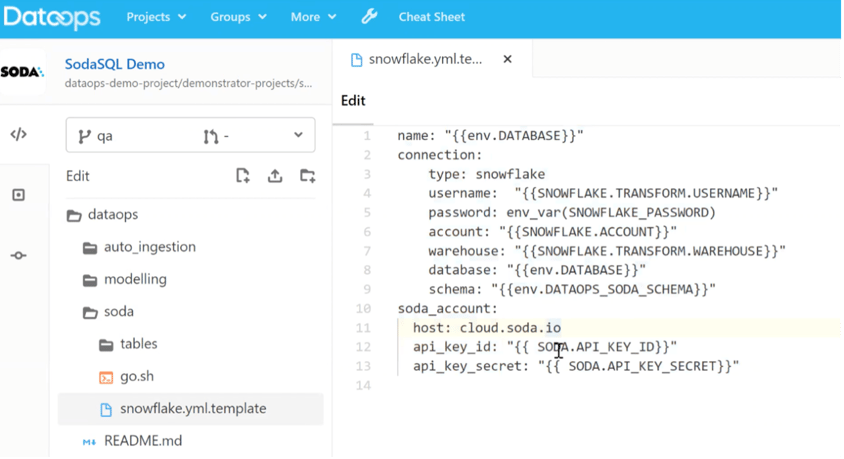
Consequently, before the Soda testing jobs are run, the Soda SQL user credentials are injected into the Snowflake template YAML file where all the credential information is kept, and all sensitive information is pulled from a secure store:
Environment Management
DataOps has implemented advanced Snowflake Environment Management functionality, allowing users to run the same tests in different environments. DataOps is able to use name spacing within Soda Cloud to separate the test results for different environments (for instance, Dev, QA, Prod).
Conclusion
The #TrueDataOps philosophy strongly advocates for automated testing. Excellent technologies like Soda SQL are giving customers more capabilities for testing that fits their unique use cases. And the current and upcoming features of Soda Cloud are adding an additional dimension beyond standard testing, with profiling and anomaly detection.
DataOps.live fully supports both Soda Cloud and Soda SQL. All DataOps customers can now use the Soda SQL tools as part of their DataOps pipelines for free. To derive the full benefits of Soda Cloud, we recommend you sign up for a Soda Cloud account to see all that they have to offer.
Ready to get started?
Sign up for your free 14 day trial of DataOps.Live on Snowflake Partner Connect today!




