
 By
DataOps.live
By
DataOps.live

In the past 2 years, the rise of the time series database (TSDB) has been meteoric—growing faster than any other database model (as defined by db-engines.com):
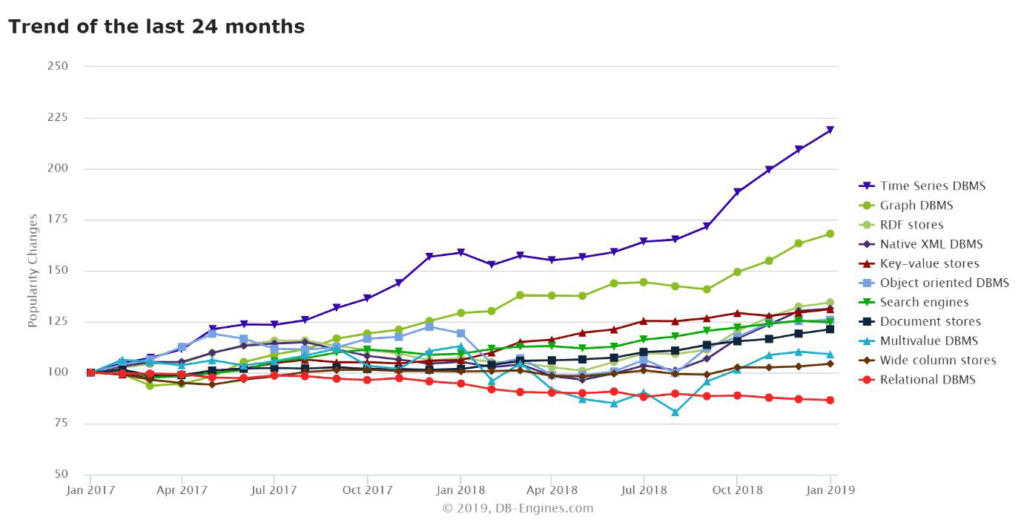
DataOps’ CTO, Guy Adams, has been focused on storing and processing time series data for over 20 years and, of course, followed this trend. In 2016 he started evaluating the best systems on the market and for a while everything looked great—these systems:
- Have very fast ingest and query of time series data
- Often have advanced time series functions
- Are very space efficient at storing time series data
- Often have nice features such as automatic ageing of old data
As a result, in a simple lab test with a large time series dataset they perform very well. The problem tends to come when a lab test turns into a more operational/production evaluation. These TSDBs typically have a similar set of challenges (not every TSDB has every challenge):
- A non-SQL and non-standard interface—fine for connecting from custom applications or for data science, but hard to connect to standard systems like BI tools and standard ETL/ELT tools (in fact TSDBs don’t really have much concept of ELT as few transforms are possible once data is loaded)
- Lack of maturity—while there are many ‘cool technologies’ in the time series database world, the overall space is still relatively niche and low volume and therefore most of these systems don’t have the deep maturity from having a very large customer base
- Only on-premise or self-hosting options—none of the benefits of a cloud database
- Relatively immutable—updates are either not supported or very slow—this is because one of the ways that a TSDB can be very fast is to store data in a way optimised for write and read but making updates extremely difficult
- Narrow focus—while time series databases get great benefits from only supporting one style of data, there is a price to pay for flexibility. In practical terms, how many organisations have JUST time series data? Usually when people say “we have a load of time series data” what they mean is “our data volume challenges are all time series, but we still have a lot of dimensional data we want to join it on to”. The problem with time series databases is that they ONLY support the time series data. When there is other information to store, another database will be needed. Using two different databases doesn’t really help since there is still no ability (without the complexity and performance hit of putting something like Presto over the top of both) to run queries and analytics using time series and non time series data at once.
In the past 18 months, Guy concluded that while the promise of time series databases was very high, the enormous flexibility, scalability and power of a cloud based SQL data warehouse like Snowflake far exceed the performance hit from being a more flexible system. Tuning of clustering using CLUSTER BY can reduce this performance hit to typically <10% which is a very small price to pay as compared to having two separate systems to maintain and a set of additional application layer development.

.png?width=400&height=250&name=Untitled%20design%20(8).png)

