
 By
DataOps.live
By
DataOps.live

Recently DataOps.live announced our support for Snowflake Java UDFs. This new Snowflake feature is another important step on the road (especially when combined with the release of Snowpark—see our blog about this here).
Java UDFs allow developers to create extremely advanced functionality in full Java code and have it run natively within Snowflake. This takes advantage of Snowflake’s powerful processing engine, for better performance, scalability and concurrency, greatly expanding the transformation capabilities and reducing management complexity from hosting external services.
In conjunction with Snowpark and other recent development has made Snowflake the first fully programmable data cloud in history.
DataOps.live enables these JAVA UDFs to be fully managed and life-cycled through development, test and production environments alongside all other objects in Snowflake.
Java UDF Development
In addition to managing all of the current objects in Snowflake (see our blog series on Imperative vs Declarative on how to manage these in Snowflake) the creation of Java UDFs presents some additional challenges for developers and users. In addition to all the normal source of truth for ‘everything data’ that we store in the DataOps git repository, we now have the all the usual software requirements. We need to branch, version, compile, test and deploy the software and produced artifacts just like any other software project.
As Snowflake continues its journey becoming the programmable data cloud, the ability to lifecycle and manage software as well as data objects is critical. The programmable data cloud means that the future of DataOps is really Data + Software.
As it happens, this fits perfectly with the #TrueDataOps philosophy which advocates “starting with pure DevOps and Agile principles (which have been battle hardened over 20+ years) and determining where they don't meet the demands of Data and adapting accordingly”.
The key requirements for developing Java UDFs in Snowflake are:
- Full development cycle and Environment Management e.g. Feature Branch->Dev->QA->PROD
- Full code lifecycle, diffs, Merge Requests, roll back etc
- Fully git compatible so continue to use IDE and Development tools of your choice
Java UDF Deployment
Building on top of the Development requirements, once the source code is in a particular branch it needs to be deployed into Snowflake. This is achieved as part of a standard DataOps pipeline e.g.
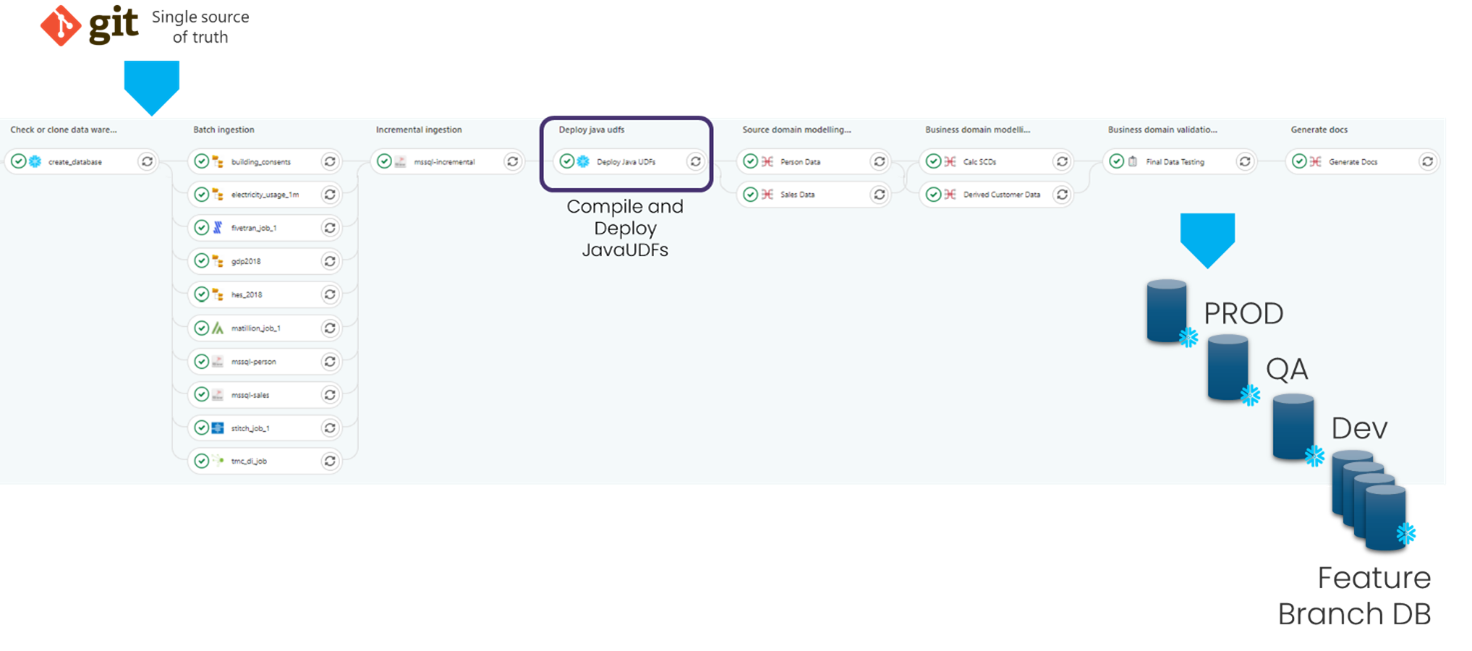
DataOps can support both inline or JAR based deployment (where the pipeline also compile JARs from Java). In these cases a Deployment stage would be preceded by a Build stage which would likely also include automated Java unit tests, ensuing the correct functionality of the UDF before it’s Deployed.
In the near future these will be managed using DataOps for Snowflake LDE (Lifecycle Declarative Engine).
Java UDF Execution
Of course, the value of a Java UDF only finally materializes when the function is actually used. These can be used in many places, but are usually deployed as part of models in the DataOps Modelling and Transformation engine e.g.
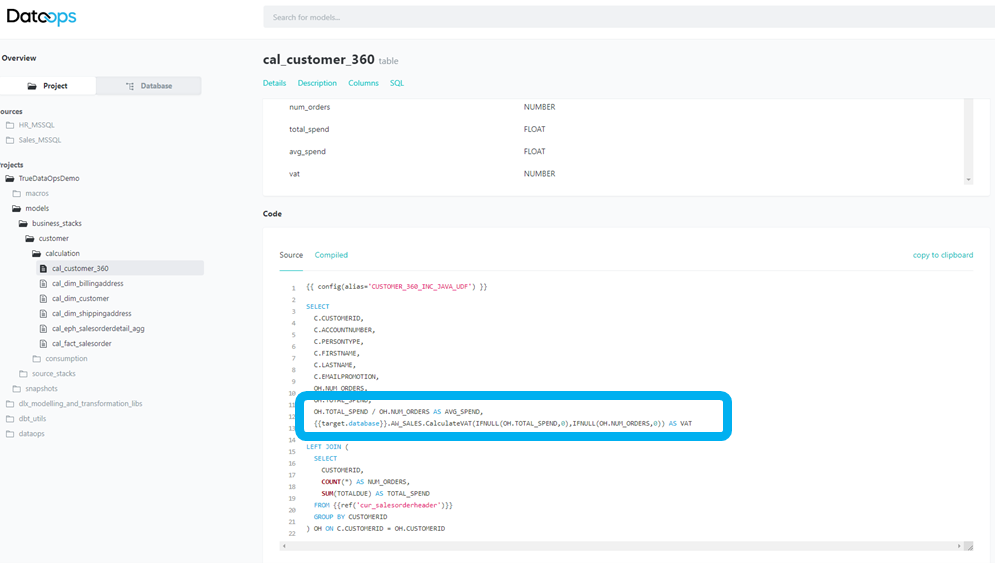
Which are then executed in a DataOps pipeline in the usual way:
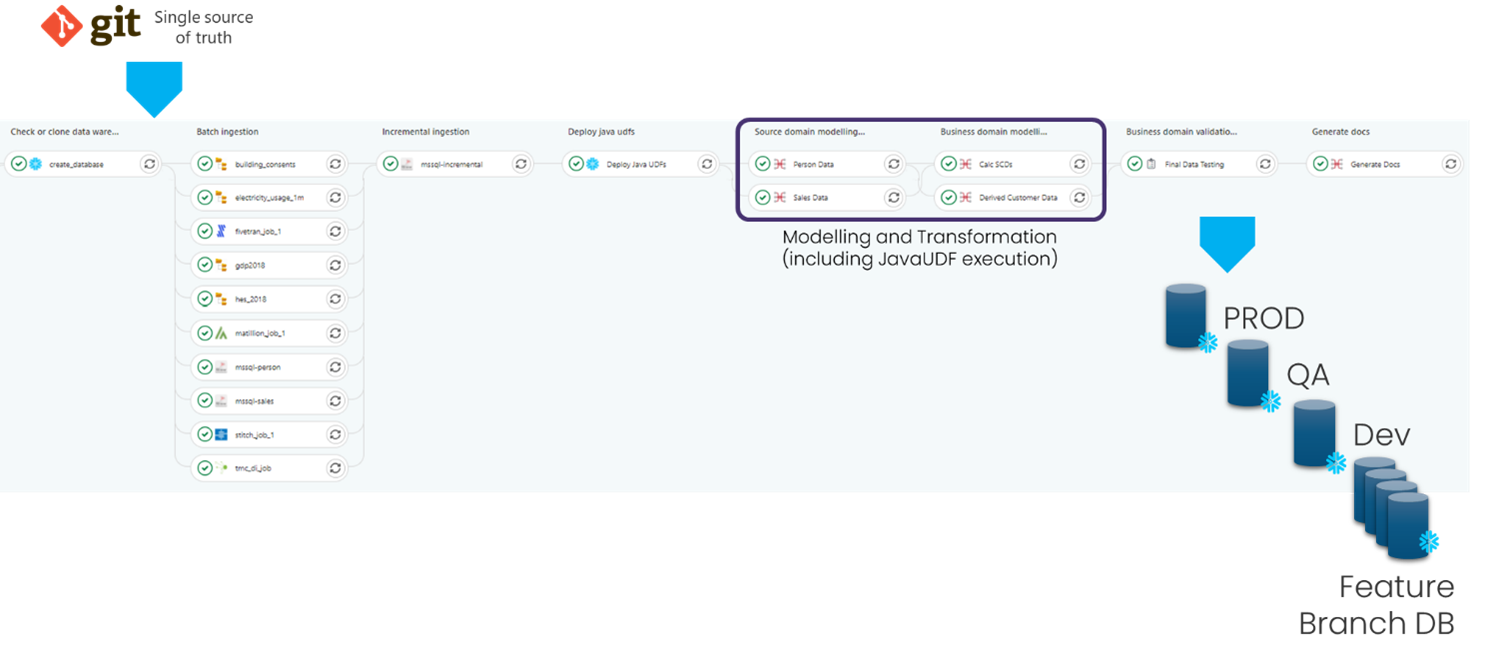
Conclusion
Java UDFs are an important new Snowflake feature—but one that creates significant new requirements in terms of management and deployment. Adding many of the requirements of the software development world to the existing Data requirements of DataOps. Despite being heavily extended for Data, DataOps.live has it’s roots in software world, and has lost none of these ability to provide complete lifecycle management and deployment of software source code like Java.
Ready to get started?
Access the latest resources on DataOps lifecycle management and support for Snowpark and Java UDFs from Snowflake.



