/banner-pink.svg)
#TrueDataOps Podcast
Snowflake Data Super Hero Keith Belanger discusses DataOps and AI with hands-on practitioners and industry leaders.
What is #TrueDataOps?
#TrueDataOps is a philosophy and a specific way of doing things that focuses on value-led development of pipelines (e.g., reduce fraud, improve customer experience, identify opportunities).
It takes the truest, battle-hardened principles of DevOps, Agile, Lean, test-driven development, and Total Quality Management and adapts and applies them to the unique discipline of data.
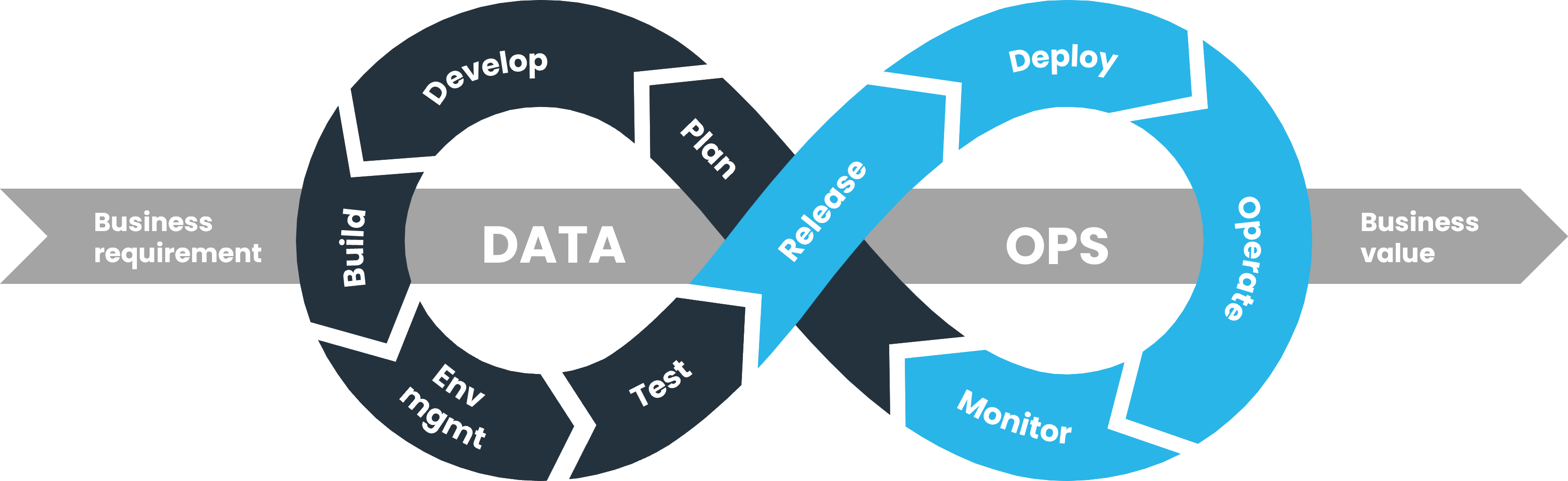
Just like DevOps, companies must embrace this philosophy before they can be successful with any DataOps project. When they do, they’ll see an order-of-magnitude improvement in quality and cycle time for data-driven operations.
The tension between governance and agility is the biggest risk to the achievement of value. It is our view that this tension doesn’t need to exist. Our experience indicates that technology has evolved to the point where governance and agility can be combined to deliver sustainable development through #TrueDataOps.
ELT and the spirit of ELT
Lift and shift data—limit ETL wherever possible
Building for the future that you can’t yet anticipate
Agility and CI/CD
Repeatable and orchestrated pipelines for building/deploying everything data
Component design and maintainability
Small atomic and testable pieces of code and configuration
Environment management
Branching data environments like we branch code
Governance, security, and change control
Grant management, anonymization, security, auditability and approvals
Automated testing and monitoring
Test-driven data development, automated test cases, external monitoring
Collaboration and self-service
Enable data access for the entire company but maintain governance
Explore the 7 Pillars of #TrueDataOps
Friction with business users based on unrealistic expectations
Business users who once would’ve been happy to get their data within a quarter now expect it within days (or faster). Rapid improvements made across the enterprise IT and software spaces have taught them that lightning-fast response times are now the norm. But many data teams still use outdated processes and technologies and are unable to keep up with these expectations. Naturally, this causes disappointment and frustration.
/Abstract%20purple%20logo.svg)
Demand always outstrips capacity
Data teams are overrun with business demands, and they simply can't keep up. They operate with big backlogs of tasks. Building integration jobs, testing and retesting jobs, assembling data pipelines, managing dev/test /production environments, and maintaining documentation are all manual tasks. They’re disconnected, slow, and prone to error.
/Abstract%20red%20logo.svg)
Manual processes reduce the capacity to fulfill requests
Minor changes to any workload that's made it through to a production environment take weeks and months to implement. This is because of the amount of manual effort that must go into the discovery, design, build, test, and deploy processes around even minor changes.
Current waterfall approaches have a major impact on agility. Too many data stores (e.g. sources >> ODS >> ETL >>DW >> ETL >> marts >> ETL >> BI tool) means any change early on (e.g., changes to a data source) has a domino effect all the way down the line. Minor changes have the potential to impact existing environments significantly; the rollback of any faulty change is even more involved.
Unplanned work further reduces output
Data teams are plagued with comments from the business: "Loading new data just takes too long” and “I can't trust the data.” Often, over 50% of the team’s time is spent on work they didn’t plan to do, or diverted to take on new governance requirements around how they acquire, process, secure, and deliver data to support the business needs.
/Abstract%20yellow%20logo.svg)
A “Wild West” of inconsistency
The issues above mean business users go around data teams. Ungoverned self-service data preparation creates a ‘wild-west’ of inconsistency and re-invention of data sets throughout the enterprise. The business ends up with various copies of the same fundamental datasets (e.g., customer info) prepared by different teams, all with different results, and no idea which to trust. Additionally, there is no corporate standard around common data names and definitions when producing data for consumption.
What we aim to achieve with DataOps
What DataOps will deliver
What elements should be included
What value an organization will get if they succeed on their DataOps journey
The DataOps manifesto
We subscribe wholeheartedly to the DataOps Manifesto.
But though the manifesto defines goals for successful DataOps adoption, it's missing the how. The manifesto does not explain the processes and philosophy behind implementation. That’s where the #TrueDataOps comes in.
We developed the #TrueDataOps philosophy to define the HOW: the way to deliver DataOps and the core pillars you need to underpin any DataOps deployment.
- How do you deliver DataOps?
- How should it operate for the developer, data manager, or data auditor?
- How does it deliver for the business stakeholder?
Using #TrueDataOps provides an order-of-magnitude improvement in quality and cycle time for data-driven operations.

Join the #TrueDataOps movement

Rethink the way you work with data. Join the #TrueDataOps movement and get regular access to DataOps content. Sign up now and get started with the DataOps for Dummies ebook.