
 By
DataOps.live
By
DataOps.live

The title’s questions: What is metadata, and can you have too much of it, are fundamental to answering the overarching question: What role does metadata play in the modern data stack?
While much has been written on the World Wide Web about the role metadata plays in the modern data ecosystem, we believe that the answers to these questions depend primarily on how the metadata is generated, enriched, and presented to the business user (or stakeholder). In other words, the following questions must be asked by the business:
- Is this metadata important?
- Does this metadata matter?
- Can we use this metadata in a secure and compliant way?
- Is this metadata trustworthy?
And, if the answer to any of these questions is in the negative, then it is worth going back to the drawing board.
Let’s expand on this concept by defining metadata and its related concepts and then considering the two primary generation and processing mechanisms.
What is metadata?
The most pervasive definition of metadata is that it is data about data. However, we feel that metadata is not only data about data. It describes the piece of data it is connected to, no matter what that data is. It summarizes key information about the data.
It is vital to note that organizations are swamped with structured and unstructured data. Both need metadata. Even though structured data is efficiently organized and stored in database tables, it still needs metadata to describe what the data in the columns mean.
For instance, a company can store a list of names, addresses, and telephone numbers in a table (or a spreadsheet). But without a table name and column headers, it is challenging to determine whether these are customer details or employee details, or even retired or fired employee details.
Conversely, because unstructured data is not stored in a structured database format, metadata describing the data elements is imperative.
Why does metadata matter?
Metadata has revolutionized data analytics in modern companies because it provides them with a competitive advantage.
The more efficient your processes to derive value in the form of meaningful insights from raw data, the more successful your business will be. Therefore, the more robust and accurate your metadata, the quicker data analysts and data scientists will be able to extract actionable information and deliver it to organizational decision-makers on time and within budget.
Metadata ultimately increases the value of organizational data because it allows data to be identified and discovered. Without metadata, a lot of an organization’s data will be unusable.
In summary, not only does metadata facilitate improved decision-making, but it also supports data quality, consistency, and governance across the entire organization.
Lastly, metadata is stored in a data catalog, an inventory of an organization’s data assets that helps the organization manage its data. It also allows data teams to collect, organize, access, and enrich their metadata.
Manual and one-click data cataloging
However, there is a caveat to this discussion. For metadata to fulfill its primary mandate, it must be insightful and add value to the organization’s data ecosystem. Therefore, let’s now consider the two most significant ways of generating and publishing metadata to a data catalog.
Our very own Guy Adams recently co-presented a Zoom masterclass with Bryon Jacobs of data.world on data cataloging, or the process of harvesting metadata and publishing it in a data catalog.
What is data.world?
The company and product, data.world, is an enterprise data catalog explicitly designed for the modern data stack. And we are proud to announce that we have integrated data.world’s data catalog as an integral part of our DataOps pipelines. More specifically, we push all the metadata we collect throughout our pipeline run and publish it to their data catalog during the last step of our pipeline run.
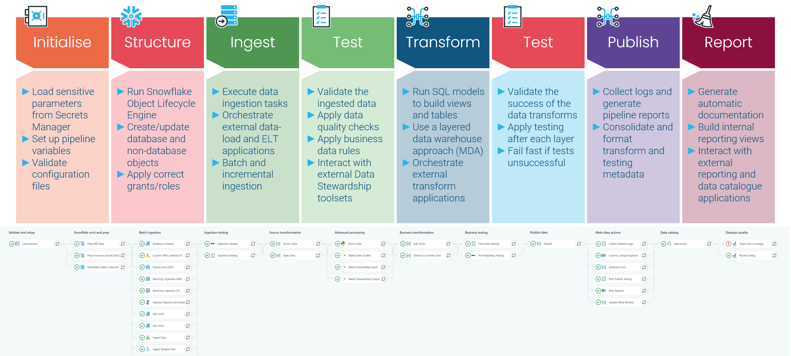
Let’s turn to the masterclass synopsis for a description of the types of metadata we collect during the end-to-end DataOps pipeline run:
“By the end of the pipeline run, we would have collected a ton of information about every step in the pipeline, such as where the data came from, what we did with it, how we transformed it, what tests were applied, what governance structures were applied, and so on.”
As noted above, there are essentially two ways to populate a data catalog: manual or one-click data-cataloging. Let’s consider a relatively short discussion on each of these topics.
- Manual data cataloging
Manual data cataloging is, in essence, a process where metadata is harvested from the organization’s disparate data sources, enriched by data stewards or personas, published to a single data catalog, and then accessed by the business.
There are two problems with this methodology:
- Too much data—Because of the massive volumes of data generated daily by organizations in today’s world, it is just not possible for data stewards to enrich all its associated metadata.
- Multiple data environments: A single data catalog—Modern organizations must now also be technical companies (irrespective of their primary income-generation mechanism). Consequently, they will have three data environments: dev, qa, and prod, each with different data at any given point in time. However, because of the manual data cataloging process, there can only ever be one data catalog, resulting in a disconnect between the multiple data environments and the single data catalog.
- One-click data cataloging
Clearly, the manual data cataloging process is untenable, especially if the business wants to drive organizational growth by deriving meaningful insights from its data to improve its decision-making.
One-click data cataloging is essentially automated data cataloging. It takes a single mouse click to start the DataOps pipeline run. And, unless there are any errors, the end-to-end DataOps process will collect all the metadata generated throughout the pipeline run, enrich it, test that it is correct and what we expect, and then push it to the environment-specific data catalog (in the last step (Report) of the DataOps pipeline).
Once the DataOps pipeline has completed its run, the data catalog is made available to business users and stakeholders.
The net effect of this automated process is that more valuable information is stored in the data catalog. This, in turn, will provide the following benefits to the business:
- Improve the quality of the metadata.
- Accelerate the time-to-value for creating valuable and meaningful reports, dashboards, and other data insights.
- Reduce the TCO (Total Cost of Ownership) and improve the ROI (Return on Investment) on the overall cost of deriving value from this metadata.
- Help the organization become a market leader in its sector by providing information that drives sustainable business growth over time.
Conclusion
To summarize this article by providing a direct answer to the questions posed in this article’s title:
What is metadata?
In short, it is data about data.
Can you have too much metadata?
Yes, and no. The answer to this question depends on whether it is helpful to the organization or not. And the best way to provide a use for all of this metadata is to generate, harvest, or scrape it and publish it to a data catalog via our one-click data cataloging method, deeply integrated into our DataOps pipelines.



