
 By
DataOps.live
By
DataOps.live

Introduction
Recently DataOps.live announced our support for Snowflake Snowpark.
Snowflake is known for its performance, scalability, and concurrency. Before Snowpark, users interacted with Snowflake predominately through SQL. Now, customers will be able to execute more workflows entirely within Snowflake’s Data Cloud, without the need to manage additional processing systems.
Snowpark enables users comfortable with other languages, such as Scala and Java, to write code that is natural for them using a widely used and familiar DataFrame model. Dataops.live enables that Scala or Java code to be stored, managed and lifecycled, and projects the latest code (depending on the environment it is run against e.g. dev, test, or production) into Snowflake (via Snowpark) every time a pipeline is run.
In conjunction with Java UDFs and other recent development has made Snowflake the first fully programmable data cloud in history.
DataOps.live enables Snowpark source code to be fully managed and life-cycled through development, test and production environments alongside all other objects in Snowflake.
How does Snowpark work
In very simple terms Snowpark libraries allow you to use standard DataFrame paradigms in code (e.g. Scala). When these are executed the Snowpark libraries transparently compile these to a combination of SQL and Java UDFs, execute them, then take the results back and convert them back to DataFrames e.g.
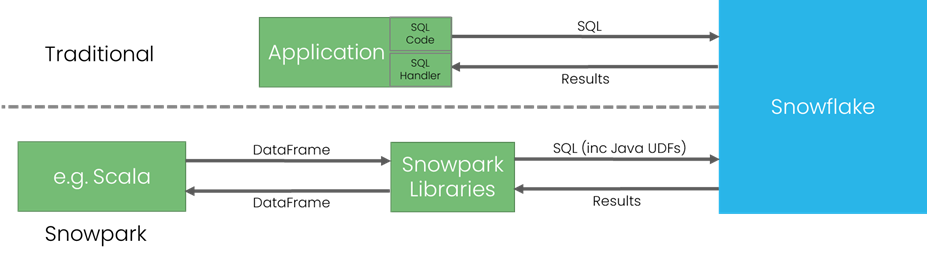
This approach is game changing for the Snowflake Developer experience.
Snowpark Development
In addition to managing all the current objects in Snowflake (see our blog series on Imperative vs Declarative on how to manage these in Snowflake) using Snowpark presents some additional challenges for developers and users. As well as all the normal source of truth for ‘everything data’ that we store in the DataOps git repository, we now have full software management requirements e.g. Scala code:
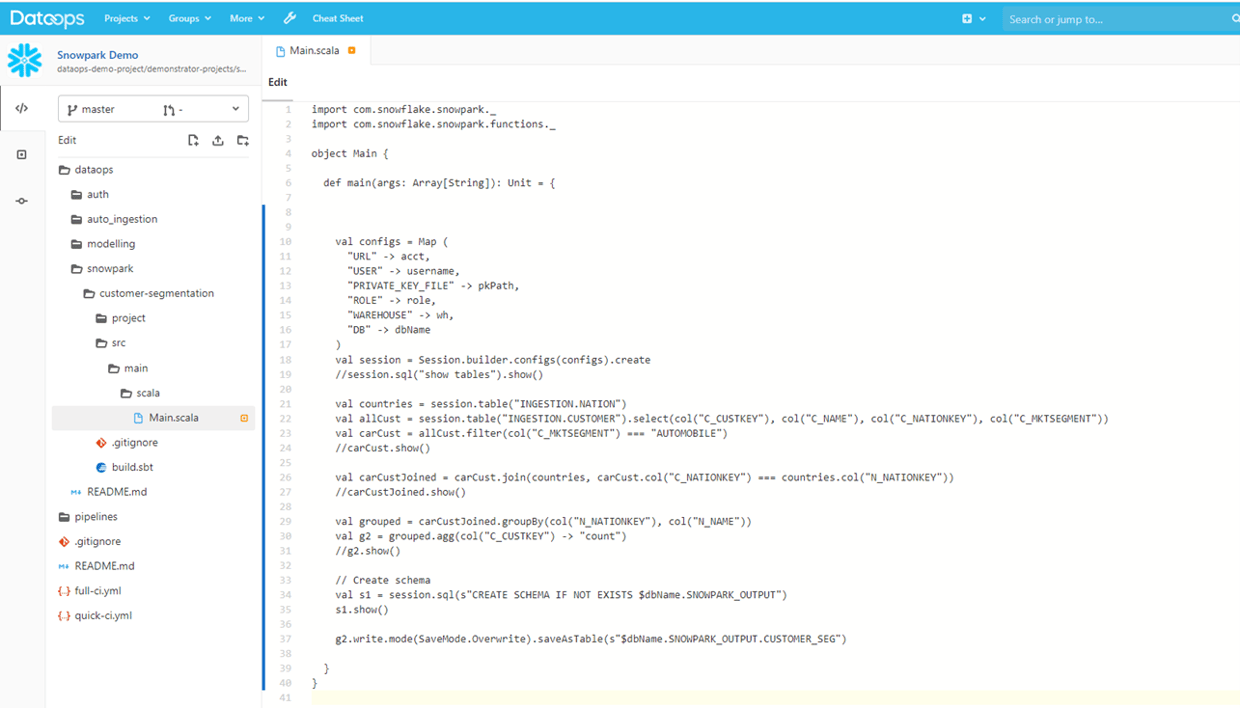
We need to branch, version, compile, test and deploy the software and produced artifacts just like any other software project.
As Snowflake continues its journey becoming the programmable data cloud, the ability to lifecycle and manage software code as well as data objects is critical. The programmable data cloud means that the future of DataOps is really Data + Software (code).
As it happens, this fits perfectly with the #TrueDataops philosophy which advocates “starting with pure DevOps and Agile principles (which have been battle hardened over 20+ years) and determining where they don't meet the demands of Data and adapting accordingly”.
The key requirements for developing with Snowpark are:
- Full development cycle and Environment Management e.g. Feature Branch->Dev->QA->PROD
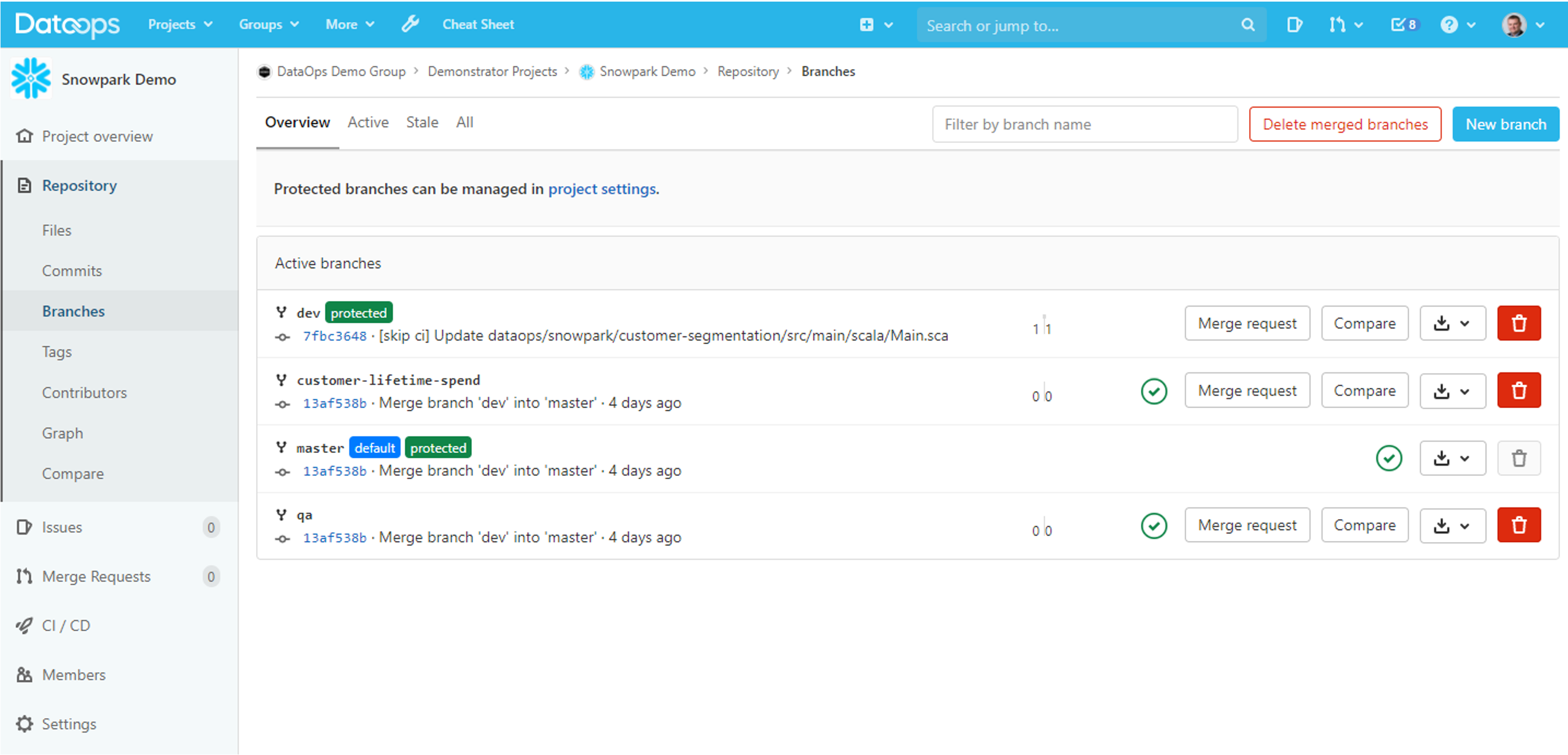
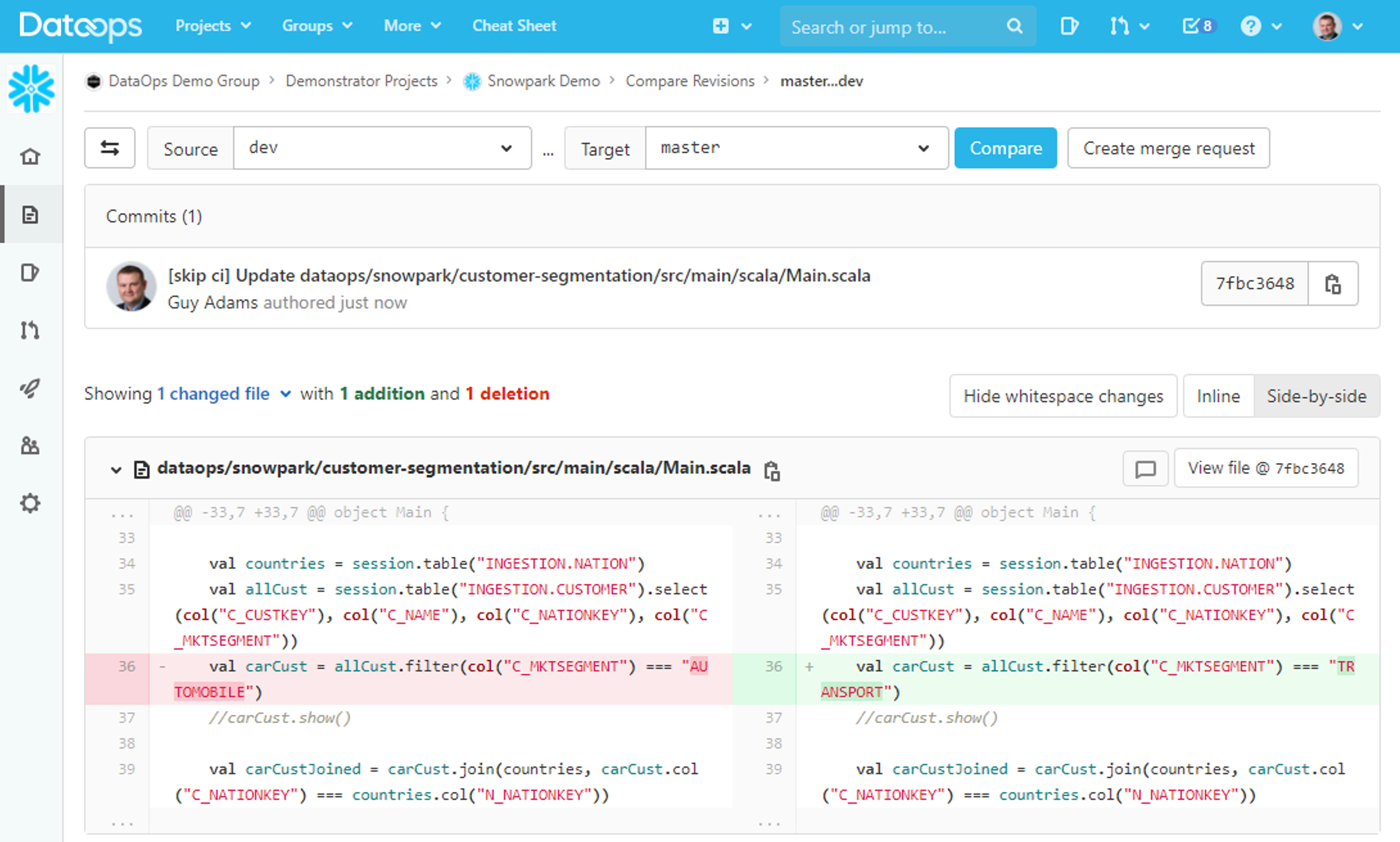
- Full code lifecycle, diffs, Merge Requests, roll back etc:
- Fully git compatible so continue to use IDE and Development tools of your choice
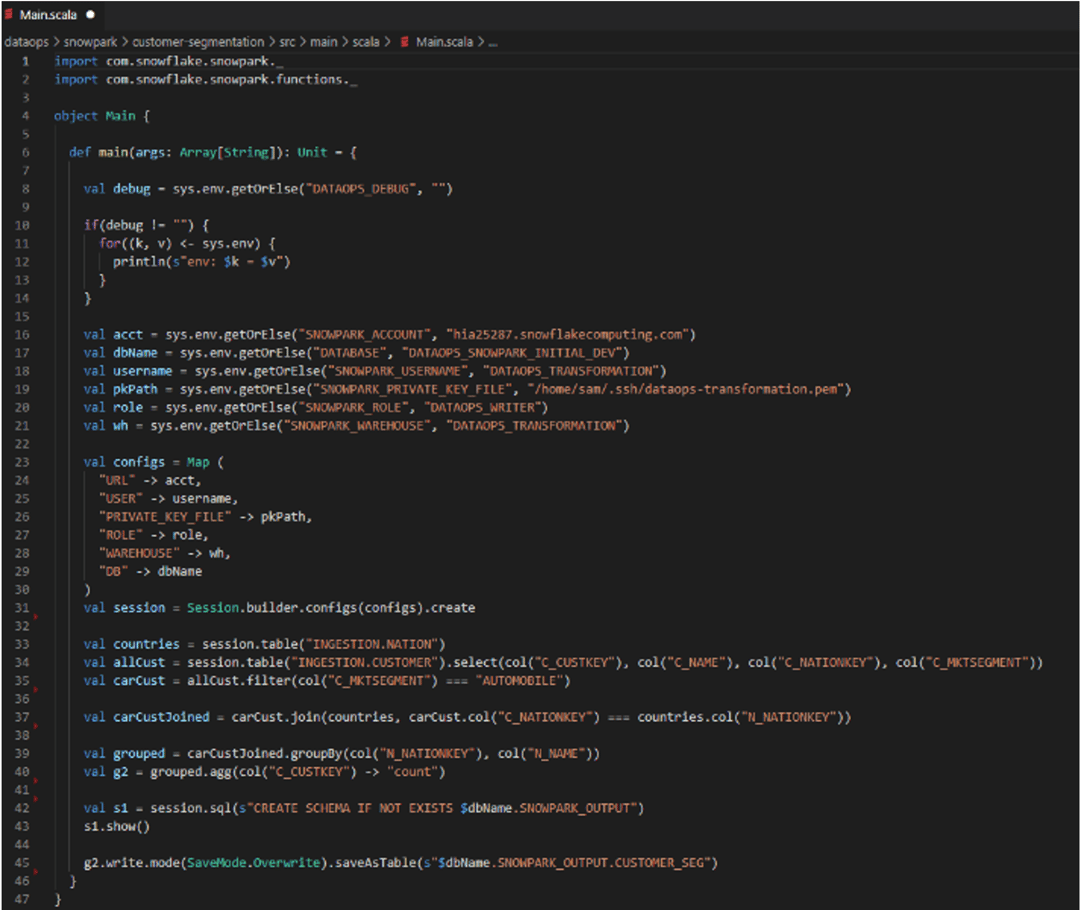
Snowpark Execution
Running a Snowpark really means running of the application in which the Snowpark libraries are being used. For example, if Scala is being used then an environment is needed with all the runtime tools for each specific language and libraries (plus the Snowpark libraries themselves) e.g.
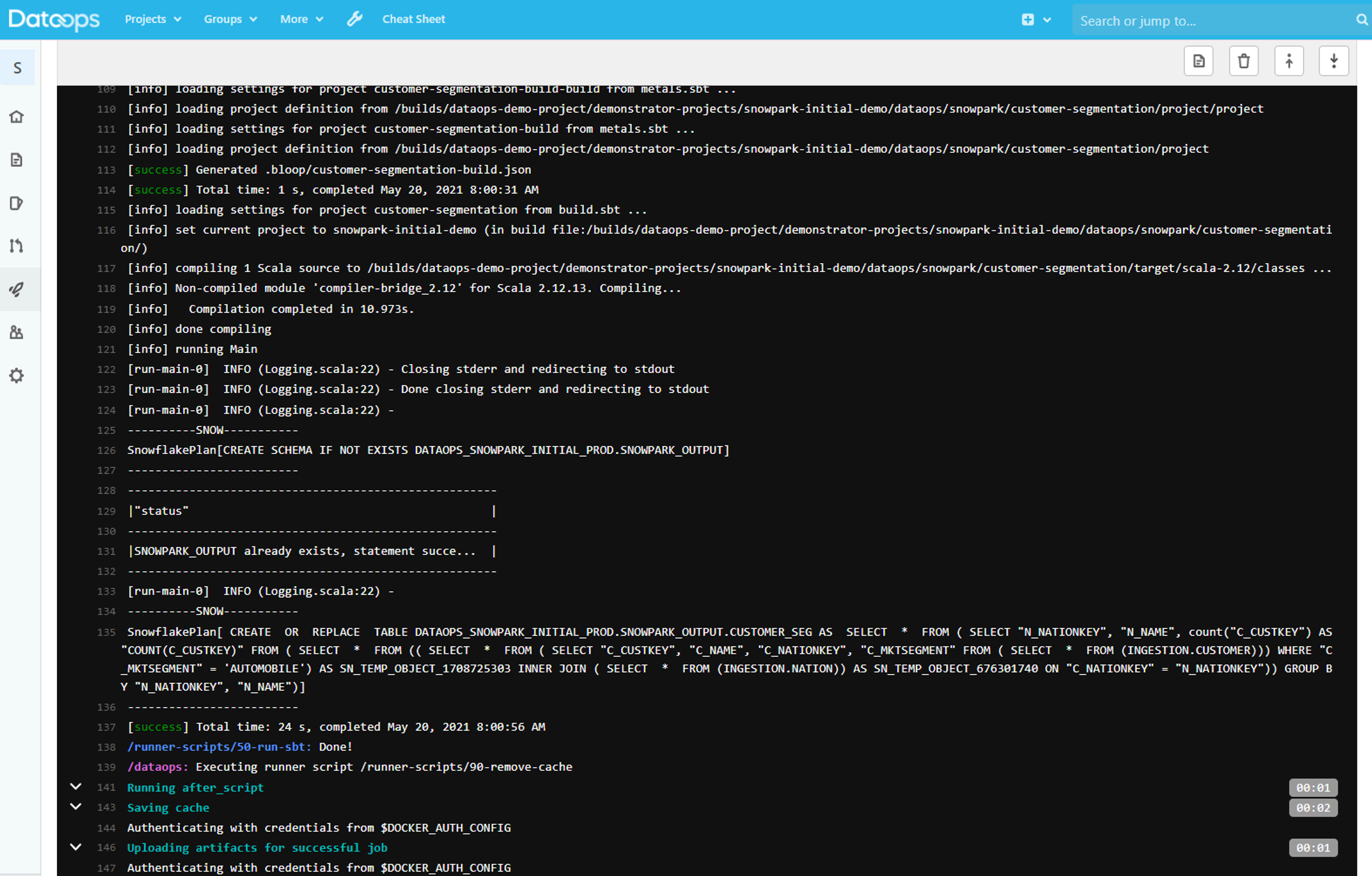
Fortunately, DataOps.live provides an execution environment (we call them runners) which can be run anywhere a customer needs, including in a Private Cloud or on prem e.g.
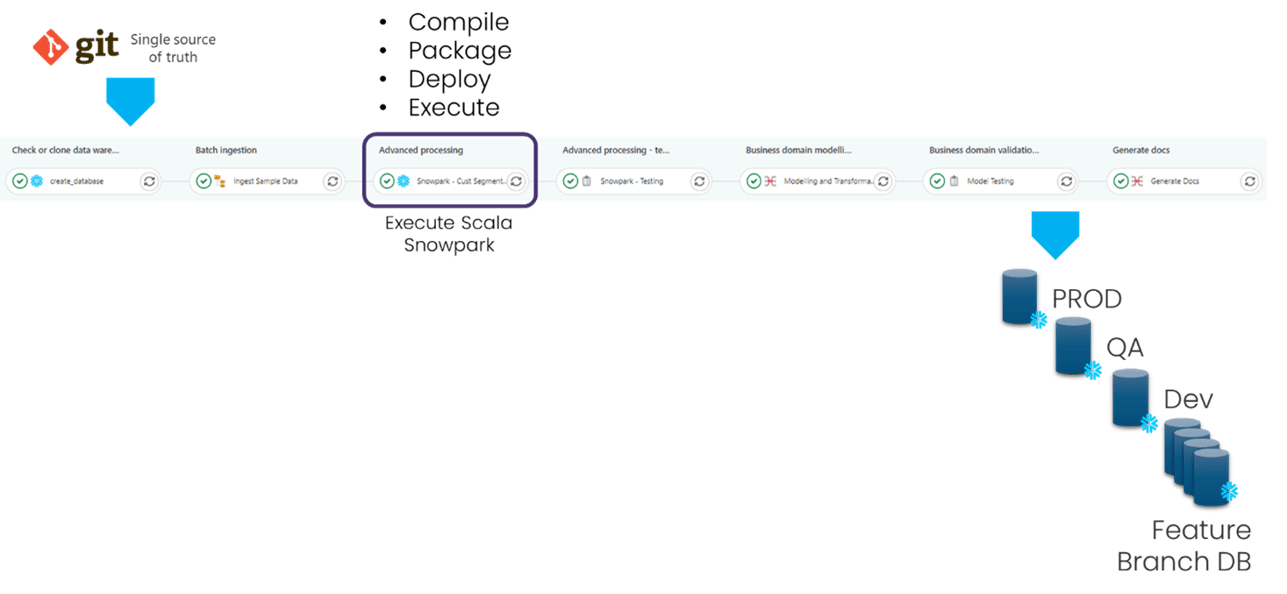
The use of this Snowpark runner abstracts all of the complexity and dependency management and makes running a Snowpark application as part of a DataOps pipeline as simple as:
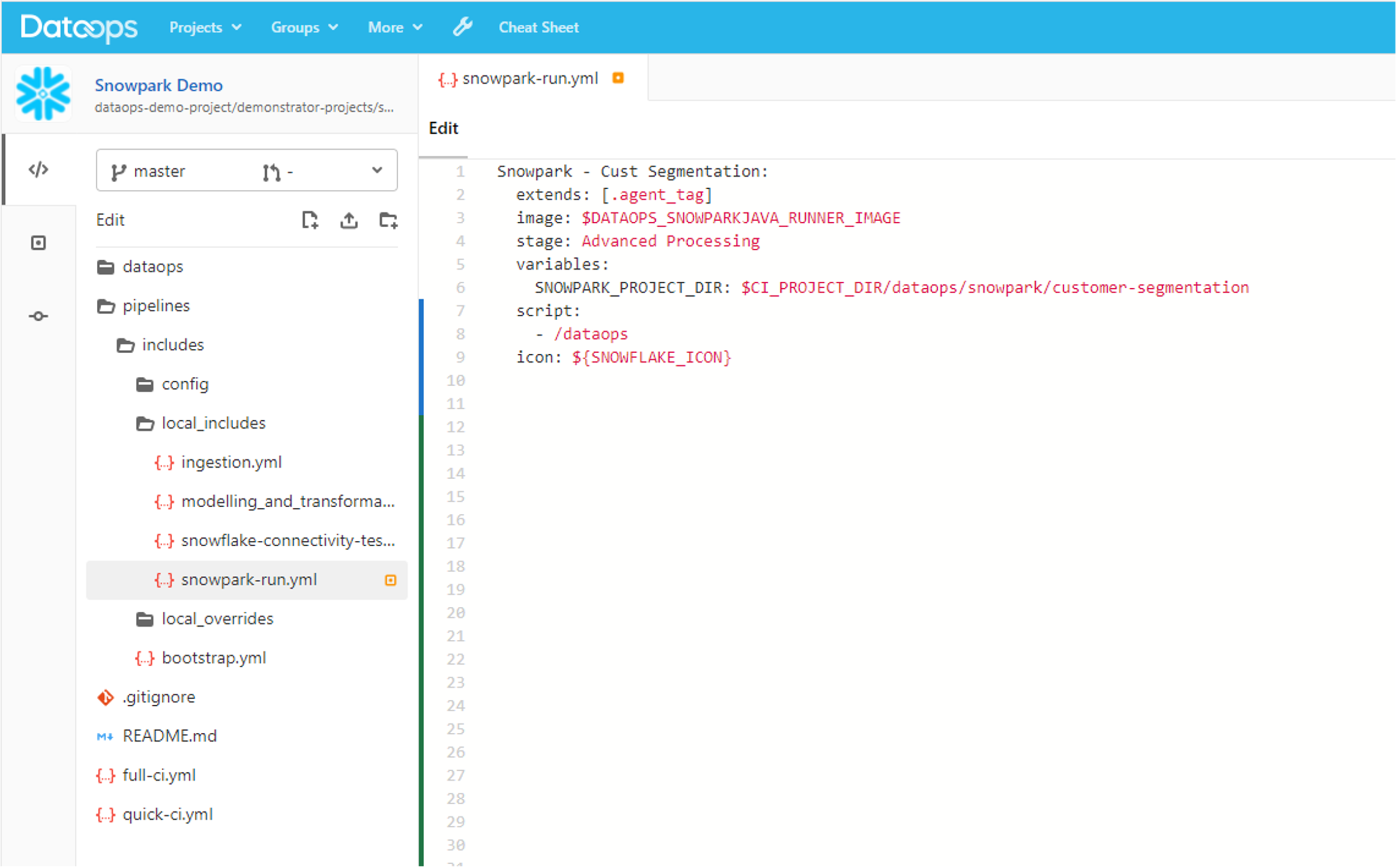
In many cases a Snowpark application will be used to do advanced data manipulation, in particular manipulation beyond what can be achieved within SQL, but with results still stored back into Snowflake. In these cases the automated Data testing within the DataOps Modelling and Transformation Engine can be used to validate the results of the Snowpark application:
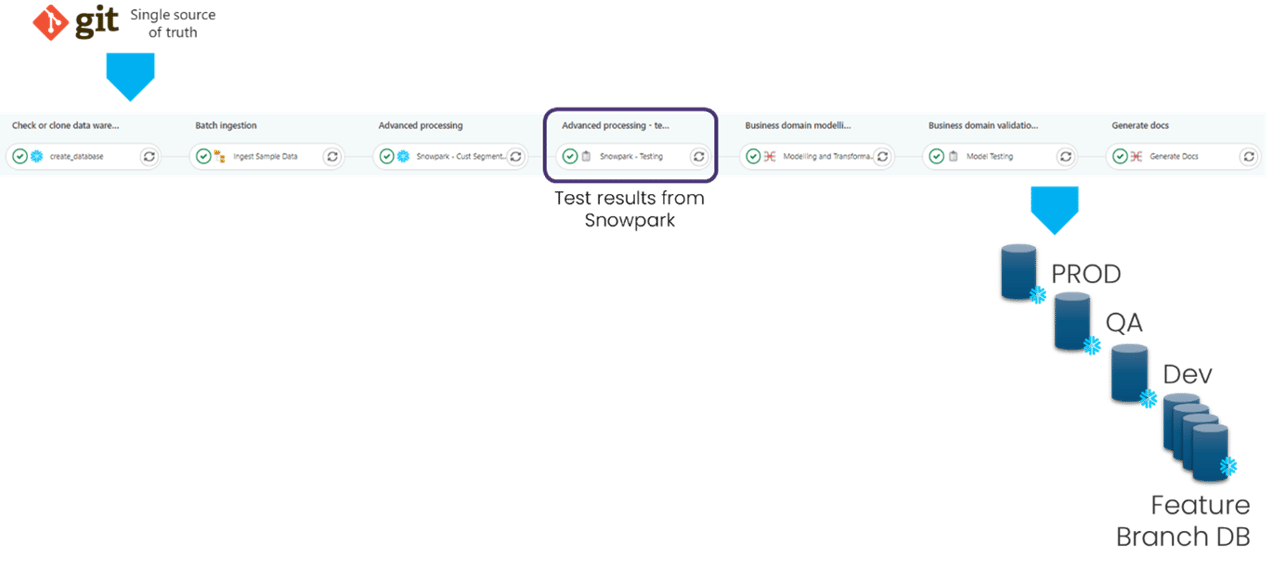
In practice in a realistic Snowpark scenario, many Snowpark applications may need executing, at different points in a pipeline, interspersed with ingestion, transformation, testing, data sharing etc with all the correct dependencies modelled and tested. This orchestration of Snowpark applications as part of a complete end to end pipeline.
Conclusion
Snowpark is a transformational new Snowflake feature but ones that creates new requirements in terms of management and deployment, adding many of the requirements of the software development world to the existing Data requirements of DataOps. Despite being heavily extended for Data, DataOps.live has it’s roots in software world, and has lost none of these ability to provide complete lifecycle management and deployment of software source code like that used in Snowpark. In addition, DataOps.live provides turn key, fully tested execution environments to make running a Snowpark application.
Ready to get started?
Access the latest resources on DataOps lifecycle management and support for Snowpark and Java UDFs from Snowflake.



