
 By
DataOps.live
By
DataOps.live

The cloud data warehouse or data cloud is increasing in importance exponentially as more organizations understand the value of using data-driven insights as a foundation for and critical part of any decision-making process. As a result, it is essential to move unstructured, structured, and semi-structured raw data from its source to a centralized location (the cloud data warehouse) to be processed, transformed, modeled, and analyzed to derive meaningful insights or information.
Thus, the question begs: How is this data transferred from multiple sources into the Snowflake data cloud?
The straightforward answer to this question is that the traditional solution is to ETL (Extract, Transform, Load) the data from source to destination. Before the development and popularity of cloud data warehouses, the data was loaded into a staging area, where it was transformed before loading into its destination.
However, because the data cloud architecture is exponentially more scalable than the traditional data warehouse in terms of storage and compute capabilities, the "T" and "L" in ETL are swapped around to create ELT (Extract, Load, Transform); a design pattern where the data is loaded into the data cloud before it is transformed. In other words, cloud-native ELT is designed to leverage the data cloud's elastic scalability, massively parallel processing capability, and the ability to spin up and tear down jobs or environments quickly and easily.
DataOps.live and Matillion ETL
Because DataOps.live is an end-to-end orchestration platform that sits on top of the Snowflake data cloud, its primary function is to integrate with and orchestrate a wide variety of functional tools such as Talend, SodaSQL, Fivetran, Stitch, Informatica, and AWS, among others and now Matillion.
While it is important to be aware of the wide variety of tools that DataOps integrates with, the sole function of this article is to discuss our integration with the Matillion ETL tools.
Even though it’s called Matillion ETL, it is actually highly effective at ELT. It is designed to extract data from multiple disparate data sources and load it into the Snowflake data cloud. We have integrated Matillion with DataOps by developing the Matillion DataOps orchestrator that connects to Matillion and orchestrates all aspects of a Matillion instance including ingestion jobs into Snowflake.
The benefits of ingesting data from Matillion from within DataOps.live
The salient point is that DataOps is an orchestration platform. It orchestrates tools like Matillion to perform the role they were initially intended for, providing several significant benefits to organizations by adding extra functionality on top of the tool’s default functionality.
Let’s expand on this statement by considering the benefits of using DataOps to orchestrate your Matillion ELT functionality within an end-to-end data pipeline.
Before we look at our Matillion orchestrator functionality in detail by way of highlighting the benefits of signing up with DataOps.live to orchestrate your data pipelines, let’s consider its range of capabilities as described in the following three sentences:
- Kick off the Matillion ELT job by connecting to the Matillion API
- Poll the API for the success: true/false indicator
- If success = true, propagate the success data
1. Orchestrate any number of Matillion servers
We can orchestrate any number of Matillion servers in a single pipeline.
Matillion infrastructure
Matillion ETL is primarily an appliance, or virtual machine (VM) installed on your infrastructure, whether on-premises, private cloud, or located in a private data center. Each Matillion ETL instance is individually managed. There is no overarching management infrastructure or agent.
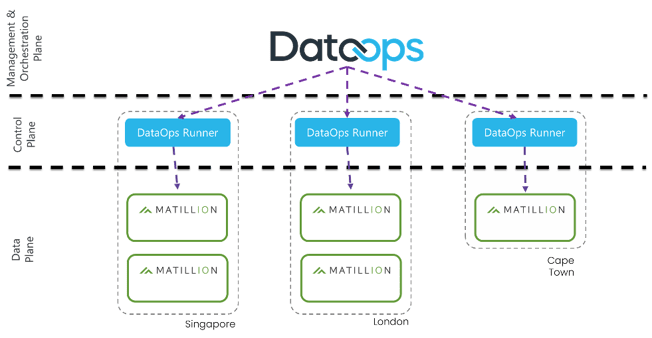
This image shows the structure of the orchestrator architecture. In summary, you can run any number of DataOps orchestrator in different environments such as private clouds, on-premises servers, and data centers, providing the functionality to communicate with different tools in various locations without crossing network boundaries.
For instance, if you are a DataOps customer with data centers in Singapore, London, and Cape Town; a separate Matillion instance will be installed on your servers in each data center. These instances do not know of each other’s existence and do not talk to each other.
Therefore, if you need to talk to a Matillion VM hosted in Singapore, we install a local agent on this Matillion VM in Singapore. Additionally, we can talk to any number of Matillion instances in different parts of the world, each instance behind its own firewall. We implement the concept of local agents or DataOps orchestrators that we install behind each firewall and co-locate or install them close to the Matillion VM that they will interface with.
In summary, the orchestrators (formerly called runners) sit behind the client’s firewalls and dial out or home.
The DataOps/Matillion orchestrator code
As noted above, the Matillion ETL tool does not include a high-level management or orchestration layer. Therefore, DataOps provides this functionality when it orchestrates pipeline jobs. For instance, in one DataOps pipeline, you can have jobs pulling data from n number of Matillion VMs on multiple continents one after each other, in any order based on their dependencies. All you need to do is provide our Matillion orchestrator with the IP address of each appliance.
When run as part of a DataOps pipeline, the following occurs:
- The job calls the API, sending the job variables together with the call.
- A response is received—Success: True or False + the job instance ID.
- If successful, the job is queued; otherwise, the job stops, and the DataOps pipeline fails.
- The Matillion VM now runs this job in the background with the DataOps orchestrator polling the job every five seconds, fetching the job’s progress.
- Once the job has finished, we interrogate the API endpoint for all the job’s metadata, including when it started, when it ended, who ran it, as well as the complete breakdown of every one of the tasks included in the job.
- Once we have received a dump of all this information, the job successfully exits with the job instance ID.
In summary, within each Matillion instance, you can have as many Matillion jobs in a single pipeline as you like. You can sequence them in any order and create dependencies between them. As a result, you can implement complex orchestrations of all these individual jobs. Our DataOps pipeline is just controlling who does what and when. Matillion still takes care of the physical “boots-on-the-ground” work.
Simplicity
Orchestrating a Matillion job is as simple as a few lines of configuration:
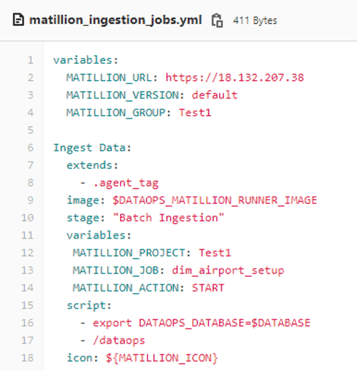
The job:
Contains all the logs of initiating the job:

Monitoring its progress:
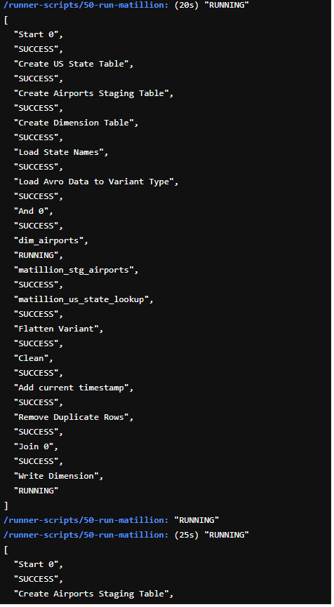
And collecting all the log and status information when a job completes successfully:
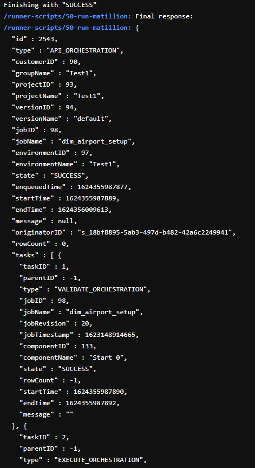
Or if it’s unsuccessful:
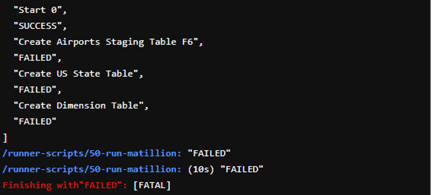
2. Environment Management
DataOps maps many different git branches and CI pipelines (e.g., master, qa, dev, feature branches) with different environments within Snowflake (e.g. PROD, QA, DEV, FBs). Ultimately, each pipeline is responsible for creating a separate Snowflake instance (environment). The DataOps environment management system manages all these environments, with Matillion being fully integrated into this system.
For instance, when we kick off a Dev pipeline, our orchestrator tells Matillion to extract the data from the Matillion instance and load it into the Dev database. When we run the same pipeline in QA, the Matillion orchestrator ensures that the extracted data is load to the QA database.
In other words, we do end-to-end environment management, and our environment management system ensures that the Matillion orchestrator knows which Snowflake environment that Matillion must operate with.
3. End-to-end dependencies
Even if you have the best ETL/ELT tool available on the market, it is still only an ETL/ELT tool. Therefore, its sole function is to extract data from its source and ingest it into its destination database when used on its own. In practice, there is very little chance that you’ll only want to extract data from its source and ingest it into its destination data source and then forget about it.
Our DataOps platform is an orchestration platform where we manage end-to-end dependencies between different tools and jobs. Therefore, because Matillion is fully integrated into DataOps, Matillion jobs are orchestrated together with all the other jobs in a DataOps pipeline. In other words, DataOps pulls all the jobs into one place and creates end-to-end dependency management.
Here is a trivial example of a DataOps pipeline:
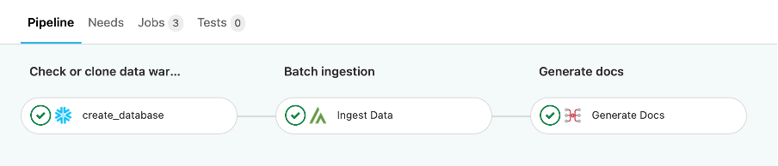
- The first job creates the database (or data warehouse).
- The second job contains the Matillion orchestrator that interfaces with a Matillion VM to extract and ingest data into Snowflake.
- The last job generates the documentation.
As highlighted above, the DataOps pipelines can get quite complex with the orchestration of many different dependency relationships. This next image illustrates a more advanced DataOps pipeline.

Pay particular note to the block of batch ingestion jobs. It is also vital to note that the order in which the jobs appear in this graphical representation is the order in which the jobs are run. In this scenario, the Matillion Ingest Data job is dependent on the first two jobs. If they don’t run successfully, then the Matillion job won’t run, and the pipeline will stop or not complete.
The second important point to note is this pipeline is ingesting data from multiple sources, including Talend, Stitch, Fivetran, and Matillion, using the orchestrator architecture.
4. Secrets Management
A centralized enterprise secrets manager forms an integral part of most DataOps pipelines. The main choices include AWS Secrets Manager or Azure Key Vault. This is because even though all the tools we orchestrate have their own way of storing passwords, most enterprise organizations require you to use a centralized secrets manager.
Very few Data ecosystem tools support enterprise secrets managers directly, creating challenges in how security is handled at an enterprise level, especially if your organizational standards are that all secrets must be stored in a centralized secrets manager. You can ask the security team for an exception to store the credentials in each tool. However, it is far simpler and far more secure to rely on the DataOps platform to manage your tools’ security credentials or secrets centrally.
As demonstrated in the previous image, the first step in most DataOps pipelines is the secrets management job. The necessary secrets are fetched out of the secrets manager, temporarily locally and encrypted and passed to the individual jobs needed. Once the pipeline has finished running, the secrets are destroyed.
You no longer need to worry about Matillion storing Snowflake credentials. DataOps does the heavy lifting by storing them in a secure enterprise secrets manager and passes them into Matillion at runtime.
5. DataBase Change Management
A standard or everyday use case for Matillion is data ingestion. In other words, extract data from its source and load it into Snowflake. A significant challenge for any database or data warehouse administrator is the schema management to ensure that the tables and columns align with the data both in the source and destination databases.
In our scenario, the often-asked question is how do you manage the schema and structure of the tables that Matillion is writing to? In particular, how do you add a new column to one (or more) of these tables?
It is challenging in a traditional, imperative-based programming environment. You can run scripts containing DDL SQL ALTER TABLE, ADD COLUMN statements, but this quickly becomes a problem managing many of these scripts without needing to rerun scripts because of errors and failed statements.
We use our Snowflake Object Lifecycle Engine (SOLE) to implement database change management to solve this problem.
SOLE is a declarative engine that looks at the current state of a database and determines how close it is to a perfect state as described in YAML files. In other words, you model what the database must look like in YAML files, and SOLE uses this to ensure that, when a pipeline is run, the database represents the state described in the YAML files.
Defining a table using SOLE is as simple as:
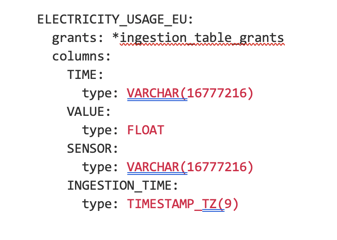
6. GIT Integration
Git integration is an important benefit of using DataOps to orchestrate your data pipelines.
For instance, a business requirement is to add a new column to a Snowflake table that will store the aggregated sales total per line of products sold for a predetermined period, such as quarterly.
This column must be added to the SOLE scripts to ensure that the column already exists or is created when the pipeline is run. It must also be added to the Matillion job that our Matillion orchestrator calls.
We can also integrate Matillion with our Git backend repository. Therefore, we can use the DataOps Git repository as the Matillion Git Repository. As a result, you can coordinate Matillion changes with DataOps changes and test and merge these changes with the code in all the other environments.
Ready to get started?
Sign up for your free 14 day trial of DataOps.Live on Snowflake Partner Connect today!




